
使用机器学习给自己推荐番剧:first try
花费许多时间学到的东西自然是要用一用的,如果工作中用不到的话,那就用来为生活增添些许乐趣吧。
看番多年,难免遇到烂番,既浪费时间,又影响心情;另外,有些优秀的番剧,可能因为某些原因,与自己失之交臂。要是能在自己看过的番剧的基础上,建立一个模型,帮自己避免烂番,发掘好番,那真是再好不过了。于是我就把自己近年来看过的番剧整理了一下,收集了若干相关信息,做成了excel表格,作为建立模型的原材料。数据是手动整理的,花费的时间比我预计的多很多,但在整理的过程中,也引发了不少回忆,所以也算不上是浪费时间。
A.关于数据
数据就是我看番的记录,不全,但应该是足够用了。反应变量是我对某番剧的评分,从5分到10分,是离散数据,在这第一次尝试中,计划将其变为二元分类数据,即5分到7分为不推荐,8分到10分为推荐。预测变量有十来个,包括番剧的年代、类型、制作公司、声优和网站评分等信息,在第一次尝试中,计划把数据弄成稀疏矩阵,使用朴素贝叶斯算法和规则学习算法来进行分类。
在查看数据之前,先载入分析需要用到的包:
library(tidyverse)
library(readxl)
library(here)
library(ggthemes)
library(corrplot)
library(tidytext)
library(widyr)
library(igraph)
library(ggraph)
library(e1071)
library(RWeka)
library(gmodels)然后导入数据,并进行初步的清洗:
anime <- read_xlsx(here('content', 'post', 'data', 'anime_record.xlsx')) %>%
mutate_all(str_remove_all, pattern = '\U00A0') %>% # 去掉不间断空格<U+00A0>
select(-record_time) %>%
mutate(studio = str_remove(studio, ',.*')) %>%
mutate_at(vars(c('season_number', 'episode', 'year', 'rating',
'db_number', 'mal_number')), as.integer) %>%
mutate_at(vars(c('db_rating', 'mal_rating')), as.numeric)看一下数据的情况:
glimpse(anime)## Observations: 186
## Variables: 15
## $ name <chr> "新世纪福音战士", "钢之炼金术师", "妖精的旋律", "蔷薇少女", "地狱少女", "蔷...
## $ series <chr> "新世纪福音战士", "钢之炼金术师", "妖精的旋律", "蔷薇少女", "地狱少女", "蔷...
## $ season_number <int> 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, ...
## $ episode <int> 26, 51, 13, 12, 26, 12, 24, 24, 14, 24, 26, 25, ...
## $ year <int> 1995, 2003, 2004, 2004, 2005, 2005, 2005, 2006, ...
## $ season <chr> "秋", "秋", "夏", "秋", "秋", "秋", "秋", "冬", "春", "春"...
## $ origin <chr> "原创", "漫改", "漫改", "漫改", "原创", "漫改", "轻改", "游改", ...
## $ genra <chr> "Action,Dementia,Drama,Mecha,Psychological,Sci-F...
## $ studio <chr> "Gainax", "Bones", "Arms", "Nomad", "Studio Deen...
## $ rating <int> 8, 8, 8, 7, 7, 7, 7, 7, 10, 8, 7, 10, 10, 9, 6, ...
## $ db_rating <dbl> 9.4, 9.2, 8.2, 7.7, 7.8, 8.0, 7.4, 7.7, 8.5, 8.9...
## $ db_number <int> 69782, 48049, 13862, 6478, 17827, 2626, 12445, 2...
## $ mal_rating <dbl> 8.33, 8.27, 7.71, 7.52, 7.73, 7.72, 7.63, 7.49, ...
## $ mal_number <int> 416593, 538905, 562900, 77500, 90143, 48980, 193...
## $ cast <chr> "绪方惠美/林原惠美/三石琴乃/宫村优子/山口由里子/立木文彦/清川元梦/山寺宏一/关智一/岩永...可以看到,共有186行数据,15列变量。下面简单介绍下变量:
name:番剧的名称;
series:番剧的系列名,也就是番剧第一季的名字;
season_number:番剧的季数;
episode:番剧的总集数;
year:番剧首播的年份;
season:番剧首播的季节;
origin;番剧的来源,即由什么而改编;
genra:番剧的类型;
studio:番剧的制作公司;
rating;我个人对番剧的评分,即反应变量;
db_rating:豆瓣上对番剧的评分;
db_number:豆瓣上对番剧评分的人数;
mal_rating:MAL上对番剧的评分;
mal_number:MAL上对番剧评分的人数;
cast:番剧的声优
其实还有很多其他信息可以收集的,如监督、配乐、原画、作者、销量等信息,但我都没有记录,因为觉得这些信息对我看不看某个番剧没有太大的影响(毕竟人方面主要还是看声优,监督是谁,一般并不关心;而销量也没怎么关注过)。
变量介绍到此,下面开始对数据进行探索。
B.数据探索
探索前说一下缺失值的问题。整份数据中只有2个缺失值,是《死亡笔记》的豆瓣评分和豆瓣人数,因为被和谐的原因,竟然在豆瓣上连个条目都没有。不过,在最后建模的时候,我也没有用到这两个变量,所以这个问题不算个问题。
在后面的数据探索中,我频繁地使用同样的几行代码对数据进行统计,为了节省代码,就先写了个函数:
my_awesome_summary <- function(data) {
data %>% summarise(N = n(), rating = mean(rating),
db_rating = mean(db_rating, na.rm = TRUE),
db_number = mean(db_number, na.rm = TRUE),
mal_rating = mean(mal_rating), mal_number = mean(mal_number))
}该函数会在分类的基础上,计算各类别的个数及若干变量的平均值。当然,最好不要用my_awesome_summary这种函数名。
b1.番名
番名肯定会对我决定看不看某个番产生一定的影响,在中二的年代,《死亡笔记》《反叛的鲁路修》这样的名字,确实很有吸引力。不过,我不知道该如何使用这一变量,所以没有在后面的模型中用到。但这一变量倒在清洗数据时发挥了一定的作用。
b2.季数
先看一下按季数进行分类的情况:
anime %>% group_by(season_number) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| season_number | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| 1 | 125 | 7.55 | 8.18 | 17152.02 | 7.85 | 242829.1 |
| 2 | 46 | 7.78 | 8.35 | 10009.17 | 8.00 | 184294.9 |
| 3 | 10 | 7.40 | 7.95 | 11612.10 | 7.88 | 108821.9 |
| 4 | 3 | 7.33 | 7.80 | 17342.00 | 7.27 | 50593.0 |
| 5 | 1 | 9.00 | 9.50 | 26317.00 | 8.63 | 38075.0 |
| 6 | 1 | 9.00 | 9.50 | 19896.00 | 8.71 | 31475.0 |
超过3季的番很少,实际上,也就只有《夏目友人帐》作到了第六季。考虑将第2季及后续的合并在一起,与第1季进行对比:
anime %>% mutate(season_state = ifelse(season_number == 1, 'first', 'second+')) %>%
group_by(season_state) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| season_state | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| first | 125 | 7.55 | 8.18 | 17152.02 | 7.85 | 242829.1 |
| second+ | 61 | 7.74 | 8.29 | 11062.00 | 7.97 | 160444.5 |
从评分来看,后续的番剧确实要比第1季的番剧要好一些,因此我有一个猜测,即如果某个番剧出了续集,则它更值得观看。筛选一下数据,进行对比:
anime %>%
mutate(season_more = ifelse(series %in% (anime %>% filter(season_number > 1) %>%
pull(series) %>% unique()), 'yes', 'no')) %>%
group_by(season_more) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| season_more | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| no | 82 | 7.40 | 8.11 | 14753.23 | 7.81 | 202685.0 |
| yes | 104 | 7.78 | 8.30 | 15448.27 | 7.96 | 226159.4 |
这样一对比就更明显了,但有一点需要注意,就是数据中的某个“没有”后续的番剧可能并不是没有后续,只是我没有去看。
第一个变量提取出来了,即有无后续。
b3.集数
下面看下集数变量的情况:
anime %>% group_by(episode) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| episode | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| 4 | 1 | 7.00 | 8.60 | 6007.00 | 8.03 | 183539.0 |
| 6 | 1 | 7.00 | 7.30 | 2778.00 | 6.60 | 10205.0 |
| 10 | 4 | 6.75 | 7.95 | 4844.50 | 7.73 | 212081.0 |
| 11 | 6 | 8.17 | 8.75 | 25299.67 | 8.27 | 180340.3 |
| 12 | 74 | 7.46 | 8.08 | 11506.42 | 7.72 | 172649.2 |
| 13 | 40 | 7.62 | 8.41 | 16667.53 | 7.98 | 175268.0 |
| 14 | 2 | 10.00 | 8.65 | 17240.50 | 7.61 | 262674.5 |
| 15 | 1 | 8.00 | 8.60 | 22429.00 | 8.35 | 403140.0 |
| 16 | 2 | 7.00 | 7.05 | 3839.00 | 7.00 | 105944.5 |
| 21 | 1 | 7.00 | 8.50 | 9951.00 | 7.66 | 65534.0 |
| 22 | 4 | 8.00 | 8.33 | 24685.50 | 8.30 | 425028.2 |
| 23 | 2 | 9.50 | 9.00 | 14174.00 | 8.39 | 289716.0 |
| 24 | 22 | 7.68 | 8.20 | 15641.68 | 8.00 | 272950.6 |
| 25 | 11 | 8.36 | 8.48 | 28003.55 | 8.37 | 453407.4 |
| 26 | 11 | 6.64 | 7.66 | 13373.00 | 7.71 | 109467.4 |
| 37 | 1 | 10.00 | NaN | NaN | 8.66 | 1139551.0 |
| 51 | 1 | 8.00 | 9.20 | 48049.00 | 8.27 | 538905.0 |
| 52 | 1 | 7.00 | 9.00 | 838.00 | 7.60 | 6491.0 |
| 64 | 1 | 10.00 | 9.60 | 53720.00 | 9.24 | 862938.0 |
集数的类型还挺多的,我对此进行了简化,将超过20集的视为长篇,不足20集的视为短篇。这里其实并没有真正的长篇,毕竟最长的也才64集(钢炼FA),不过我没有把看过的长篇统计在内,所以这么称呼也可以吧:
anime %>% mutate(episode = ifelse(episode < 20, 'short', 'long'),
episode = factor(episode, levels = c('short', 'long'))) %>%
group_by(episode) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| episode | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| short | 131 | 7.55 | 8.20 | 13455.92 | 7.81 | 175963.8 |
| long | 55 | 7.76 | 8.25 | 19239.02 | 8.08 | 310718.2 |
在我的评分中,长篇的确实更好一些,但其实这也挺危险的,因为万一是个长篇的烂番的话,那可真是让人加倍的烦躁了。
第二个变量为是否是长篇。
b4.年份
还是先看一下各年份的情况:
anime %>% group_by(year) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| year | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| 1995 | 1 | 8.00 | 9.40 | 69782.00 | 8.33 | 416593.00 |
| 2003 | 1 | 8.00 | 9.20 | 48049.00 | 8.27 | 538905.00 |
| 2004 | 2 | 7.50 | 7.95 | 10170.00 | 7.62 | 320200.00 |
| 2005 | 3 | 7.00 | 7.73 | 10966.00 | 7.69 | 110749.00 |
| 2006 | 6 | 8.67 | 8.46 | 26425.20 | 8.16 | 433357.33 |
| 2007 | 5 | 8.00 | 8.16 | 14301.60 | 7.52 | 226445.60 |
| 2008 | 8 | 8.38 | 8.59 | 28915.62 | 8.33 | 288890.50 |
| 2009 | 11 | 8.09 | 8.55 | 21519.36 | 7.95 | 218160.18 |
| 2010 | 6 | 7.33 | 8.00 | 17073.00 | 7.91 | 329771.33 |
| 2011 | 11 | 7.91 | 8.39 | 27114.55 | 8.12 | 285201.36 |
| 2012 | 14 | 7.50 | 8.26 | 17267.93 | 7.91 | 251625.21 |
| 2013 | 13 | 7.23 | 8.03 | 12966.00 | 7.77 | 217733.46 |
| 2014 | 15 | 7.53 | 8.18 | 15401.33 | 7.87 | 314657.53 |
| 2015 | 20 | 7.40 | 7.88 | 9747.45 | 7.68 | 197773.05 |
| 2016 | 15 | 7.60 | 8.38 | 16410.53 | 8.11 | 241646.60 |
| 2017 | 16 | 7.69 | 8.28 | 11513.88 | 7.99 | 170416.75 |
| 2018 | 38 | 7.34 | 8.11 | 7271.58 | 7.72 | 84959.74 |
| 2019 | 1 | 9.00 | 9.70 | 15215.00 | 9.00 | 45057.00 |
数据中的旧番挺少的,主要是因为我是对我网盘里有资源的番剧进行的整理,而很多旧番,已经找不到资源了。另外,2018年的番剧,我竟然看了38部,看来去年是挺焦虑的,需要大量看番来缓解。不过,那年番剧的整理质量似乎挺差的,高质量的番剧,主要还是集中在2008年前后。
同样为了简化,我将2015年设为节点,之前的归类为旧番,剩下的归类为新番。看一下分类后的情况:
anime %>% mutate(year = ifelse(year < 2015, 'old', 'new'),
year = factor(year, levels = c('old', 'new'))) %>%
group_by(year) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| year | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| old | 96 | 7.74 | 8.28 | 19839.66 | 7.94 | 276670.8 |
| new | 90 | 7.48 | 8.15 | 10187.38 | 7.84 | 150892.8 |
番还是老的香啊!
第三个变量就是是否为旧番了。
b5.季节
番剧一般都是在1月、4月、7月和10月开始播出,对应冬番、春番、夏番和秋番。先看一下各季节的番剧情况:
anime %>% group_by(season) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| season | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| 春 | 54 | 7.70 | 8.21 | 16097.13 | 7.88 | 240018.5 |
| 冬 | 41 | 7.59 | 8.37 | 13337.20 | 8.00 | 185731.2 |
| 秋 | 55 | 7.58 | 8.12 | 14144.80 | 7.89 | 218163.4 |
| 夏 | 36 | 7.56 | 8.18 | 17270.64 | 7.78 | 210160.7 |
就我个人的评分而言,似乎是春番更好一些,但实际上,我看番是以补为主,以追为辅,大部分的情况下,我都意识不到这部番当年是在哪个季节里播出的,所以这个变量就先不用了。
b6.来源
来源主要包括漫画、轻小说、游戏和原创,也有个别来源不明的以及由正统小说改编的,放进了其他类别里(有一个小说改编的,我错误的放进了轻改里,但忘了是哪个了)。看一下各来源的情况:
anime %>% group_by(origin) %>%
my_awesome_summary() %>%
knitr::kable(digits = 2)| origin | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| 漫改 | 90 | 7.77 | 8.52 | 17356.28 | 7.92 | 192463.5 |
| 其他 | 5 | 7.20 | 8.04 | 5778.80 | 7.70 | 66330.2 |
| 轻改 | 58 | 7.40 | 7.88 | 10436.43 | 7.86 | 244139.0 |
| 游改 | 10 | 7.90 | 8.18 | 16663.90 | 7.88 | 282510.7 |
| 原创 | 23 | 7.52 | 7.92 | 19829.43 | 7.90 | 239227.0 |
我看的番剧有一半是由漫画改编的,我对这些番剧的评分也还不错,但是,我几乎从来没有因为看过某个漫画或轻小说而去看某个动画的(没有时间啊),也不会因为看了某个番剧,觉得好看,而去追原作的(一拳超人是个例外),所以这个变量对我看不看某个番剧应该也没啥太大的影响,先放弃了。
b7.类别
番剧类别一共由30多种,先看下整体的情况:
anime %>% separate_rows(genra, sep = ',') %>%
group_by(genra) %>%
my_awesome_summary() %>%
arrange(-N) %>%
knitr::kable(digits = 2)| genra | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| Comedy | 92 | 7.55 | 8.30 | 12362.05 | 7.82 | 192869.58 |
| Action | 70 | 7.61 | 8.09 | 17106.83 | 7.93 | 292958.14 |
| School | 60 | 7.45 | 8.14 | 13528.15 | 7.79 | 213940.98 |
| Slice of Life | 58 | 7.78 | 8.40 | 17216.45 | 7.90 | 159906.62 |
| Supernatural | 58 | 7.74 | 8.36 | 19662.47 | 8.11 | 269174.21 |
| Drama | 54 | 7.94 | 8.41 | 24999.26 | 8.09 | 279575.81 |
| Romance | 47 | 7.40 | 7.99 | 11517.55 | 7.76 | 240592.87 |
| Fantasy | 45 | 7.76 | 8.26 | 21097.58 | 8.11 | 285569.42 |
| Sci-Fi | 33 | 7.79 | 7.93 | 14952.12 | 7.78 | 216789.27 |
| Seinen | 30 | 7.37 | 8.20 | 11977.47 | 7.66 | 167865.30 |
| Mystery | 29 | 7.90 | 8.46 | 17869.39 | 8.02 | 277079.72 |
| Shounen | 25 | 8.04 | 8.75 | 21719.50 | 8.21 | 338354.80 |
| Magic | 24 | 7.42 | 7.97 | 14309.79 | 7.95 | 263051.46 |
| Adventure | 20 | 7.60 | 8.48 | 12175.30 | 8.18 | 346767.65 |
| Psychological | 20 | 7.65 | 8.21 | 19453.47 | 7.88 | 315613.35 |
| SuperPower | 17 | 8.24 | 8.42 | 25527.41 | 8.19 | 400225.71 |
| Parody | 16 | 7.69 | 8.05 | 9403.25 | 7.61 | 183292.19 |
| Military | 12 | 8.25 | 8.36 | 29216.67 | 8.11 | 403922.33 |
| Ecchi | 11 | 6.82 | 7.67 | 8229.73 | 7.63 | 247873.27 |
| Horror | 10 | 7.00 | 7.64 | 15405.70 | 7.48 | 266667.10 |
| Mecha | 10 | 7.40 | 7.35 | 19267.20 | 7.50 | 246206.90 |
| Game | 9 | 7.44 | 7.73 | 9294.67 | 7.77 | 389259.67 |
| Harem | 7 | 6.57 | 7.20 | 5682.29 | 7.24 | 154537.57 |
| Historical | 7 | 8.14 | 8.81 | 7680.57 | 8.28 | 89261.43 |
| Music | 7 | 7.00 | 7.97 | 12224.00 | 7.89 | 186041.71 |
| Shoujo | 6 | 9.00 | 9.45 | 52054.00 | 8.61 | 69487.67 |
| Thriller | 6 | 8.83 | 8.78 | 23380.00 | 8.50 | 486415.83 |
| Space | 5 | 7.00 | 7.04 | 1733.00 | 7.00 | 35079.80 |
| Police | 3 | 8.67 | 8.40 | 18267.00 | 8.20 | 588147.67 |
| Dementia | 2 | 7.50 | 8.45 | 37566.50 | 7.83 | 233431.00 |
| Josei | 2 | 9.00 | 9.45 | 8624.00 | 8.73 | 44417.50 |
| Shoujo Ai | 2 | 7.00 | 7.70 | 3674.50 | 7.07 | 40518.50 |
| Sports | 2 | 7.50 | 8.90 | 8259.50 | 7.83 | 52953.00 |
| Vampire | 2 | 7.50 | 8.85 | 13636.50 | 8.56 | 296321.00 |
我看的最多的几个类别的喜剧(Comedy)、动作(Action)、校园(School)、日常(Slice of Life)和超自然(Super Natural),但我评分最高的几个类别是军事(Military)、超能力(Super Power)和少年(Shounen)(仅统计个数超过 10的),如果不统计一下的话,我自己都不知道。另外,我最不喜欢的是后宫(Harem)。记得有次跟hj师妹聊番剧,我说我最喜欢的是《凉宫春日的忧郁》,她(似乎很鄙夷地)跟我说,她不喜欢这种男性向的后宫番。首先,我想说,《凉宫》不是后宫番啊;其次,我也很讨厌后宫番啊!
计划将这一变量转换成稀疏矩阵,并去掉个数出现太少的类别。
b8.制作公司
我看的番剧共涉及到将近50个制作公司,还是先看一下整体的情况:
anime %>%
group_by(studio) %>%
my_awesome_summary() %>%
arrange(-N) %>%
knitr::kable(digits = 2)| studio | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| A-1 Pictures | 16 | 7.31 | 7.71 | 15227.56 | 7.81 | 317868.50 |
| J.C. Staff | 15 | 7.27 | 7.87 | 11284.93 | 7.68 | 140272.27 |
| Kyoto Animation | 13 | 8.38 | 8.63 | 17731.00 | 8.04 | 259475.31 |
| Studio Deen | 12 | 7.25 | 8.17 | 10774.08 | 7.84 | 135950.00 |
| Mad house | 8 | 8.38 | 8.46 | 14708.00 | 8.30 | 442931.00 |
| Shaft | 8 | 7.38 | 8.43 | 12112.88 | 7.99 | 202859.38 |
| Bones | 7 | 8.86 | 9.31 | 30097.43 | 8.68 | 474203.29 |
| Brain’s Base | 7 | 8.43 | 9.06 | 45882.00 | 8.45 | 184809.14 |
| Sunrise | 7 | 7.86 | 8.23 | 20527.71 | 8.08 | 293667.14 |
| Production I.G | 6 | 7.67 | 8.30 | 14079.50 | 7.86 | 166226.17 |
| White Fox | 6 | 8.33 | 8.53 | 13787.50 | 8.26 | 266070.67 |
| Lerche | 5 | 7.20 | 7.86 | 8175.40 | 7.78 | 184249.20 |
| Shuka | 5 | 8.40 | 9.04 | 13336.60 | 8.34 | 87420.00 |
| SilverLink. | 5 | 7.40 | 8.44 | 6791.80 | 7.81 | 149994.60 |
| ufotable | 5 | 8.20 | 8.84 | 21870.60 | 8.34 | 271011.80 |
| Wit Studio | 5 | 8.20 | 8.64 | 34170.60 | 8.05 | 405481.40 |
| Doga Kobo | 4 | 7.25 | 7.97 | 19771.00 | 7.63 | 132846.75 |
| StudioPierrot | 4 | 6.75 | 7.32 | 19858.75 | 7.25 | 385754.25 |
| AIC Build | 3 | 7.33 | 7.40 | 8502.67 | 7.42 | 251730.00 |
| Diomedea | 3 | 7.00 | 7.37 | 3347.67 | 7.22 | 66933.67 |
| feel. | 3 | 7.67 | 8.77 | 11638.67 | 8.31 | 155367.33 |
| Gonzo | 3 | 7.00 | 7.33 | 1005.67 | 6.68 | 7201.67 |
| Sate light | 3 | 5.67 | 5.73 | 999.33 | 6.83 | 17787.33 |
| Clover Works | 2 | 6.00 | 8.05 | 8494.00 | 7.62 | 108598.50 |
| David Production | 2 | 7.50 | 8.95 | 22642.50 | 7.71 | 44781.00 |
| Geno Studio | 2 | 7.50 | 8.85 | 1280.00 | 7.97 | 33665.00 |
| Kinema Citrus | 2 | 8.00 | 8.85 | 6844.50 | 8.39 | 142476.00 |
| Nomad | 2 | 7.00 | 7.85 | 4552.00 | 7.62 | 63240.00 |
| P.A. Works | 2 | 8.00 | 8.65 | 13699.50 | 8.35 | 400245.50 |
| Seven | 2 | 7.00 | 8.10 | 7988.50 | 7.48 | 94999.50 |
| Shin-Ei Animation | 2 | 7.50 | 8.70 | 6996.50 | 7.78 | 73195.50 |
| Xebec | 2 | 7.00 | 7.35 | 2025.50 | 7.28 | 81748.50 |
| 8bit | 1 | 7.00 | 8.10 | 7069.00 | 8.37 | 78138.00 |
| AIC | 1 | 6.00 | 6.70 | 691.00 | 7.44 | 26658.00 |
| Arms | 1 | 8.00 | 8.20 | 13862.00 | 7.71 | 562900.00 |
| C-Station | 1 | 7.00 | 9.30 | 3409.00 | 8.33 | 73442.00 |
| Gainax | 1 | 8.00 | 9.40 | 69782.00 | 8.33 | 416593.00 |
| Imagin | 1 | 8.00 | 8.10 | 12540.00 | 8.33 | 249632.00 |
| Kamikaze Douga | 1 | 7.00 | 7.50 | 5351.00 | 7.33 | 50269.00 |
| Orange | 1 | 8.00 | 8.90 | 17278.00 | 8.46 | 79433.00 |
| Pierrot Plus | 1 | 7.00 | 7.10 | 1525.00 | 6.71 | 14046.00 |
| Studio 3Hz | 1 | 7.00 | 7.40 | 1648.00 | 7.30 | 101380.00 |
| Tatsunoko Production | 1 | 8.00 | 8.00 | 9768.00 | 7.52 | 196840.00 |
| TMS Entertainment | 1 | 8.00 | 8.80 | 15681.00 | 8.05 | 99415.00 |
| TNK | 1 | 6.00 | 7.10 | 15272.00 | 5.95 | 242096.00 |
| Trigger | 1 | 6.00 | 6.80 | 1352.00 | 7.27 | 115457.00 |
| TROYCA | 1 | 7.00 | 7.40 | 5314.00 | 7.46 | 62885.00 |
看的最多的三个制作公司分别是A-1,节操社(J.C. Staff)和京阿尼(Kyoto Animation),没想到我竟然看了那么多节操社的作品。为了更直观的对比,我选择个数超过5的11个公司,对评分进行了可视化:
anime %>%
group_by(studio) %>%
my_awesome_summary() %>%
filter(N > 5) %>%
gather(rater, score, c('rating', 'db_rating', 'mal_rating')) %>%
select(studio, rater, score) %>%
ggplot(aes(studio, score, fill = rater)) +
geom_col(aes(group = rater), position = 'dodge') +
scale_x_discrete(labels = c('A-1\nPictures', 'Bones', "Brain's\nBase", 'J.C.\nStaff',
'Kyoto\nAnimation', 'Mad\nhouse', 'Production\nI.G',
'Shaft', 'Studio\nDeen', 'Sunrise', 'White\nFox')) +
scale_y_continuous(breaks = 1:10, labels = 1:10) +
coord_cartesian(ylim = 1:10) +
scale_fill_manual(values = c('#009E73', '#E69F00', '#56B4E9'),
labels = c('豆瓣评分', 'MAL评分', '个人评分')) +
labs(x = '', y = '', fill = '') +
theme_tufte() +
theme(legend.position = 'top')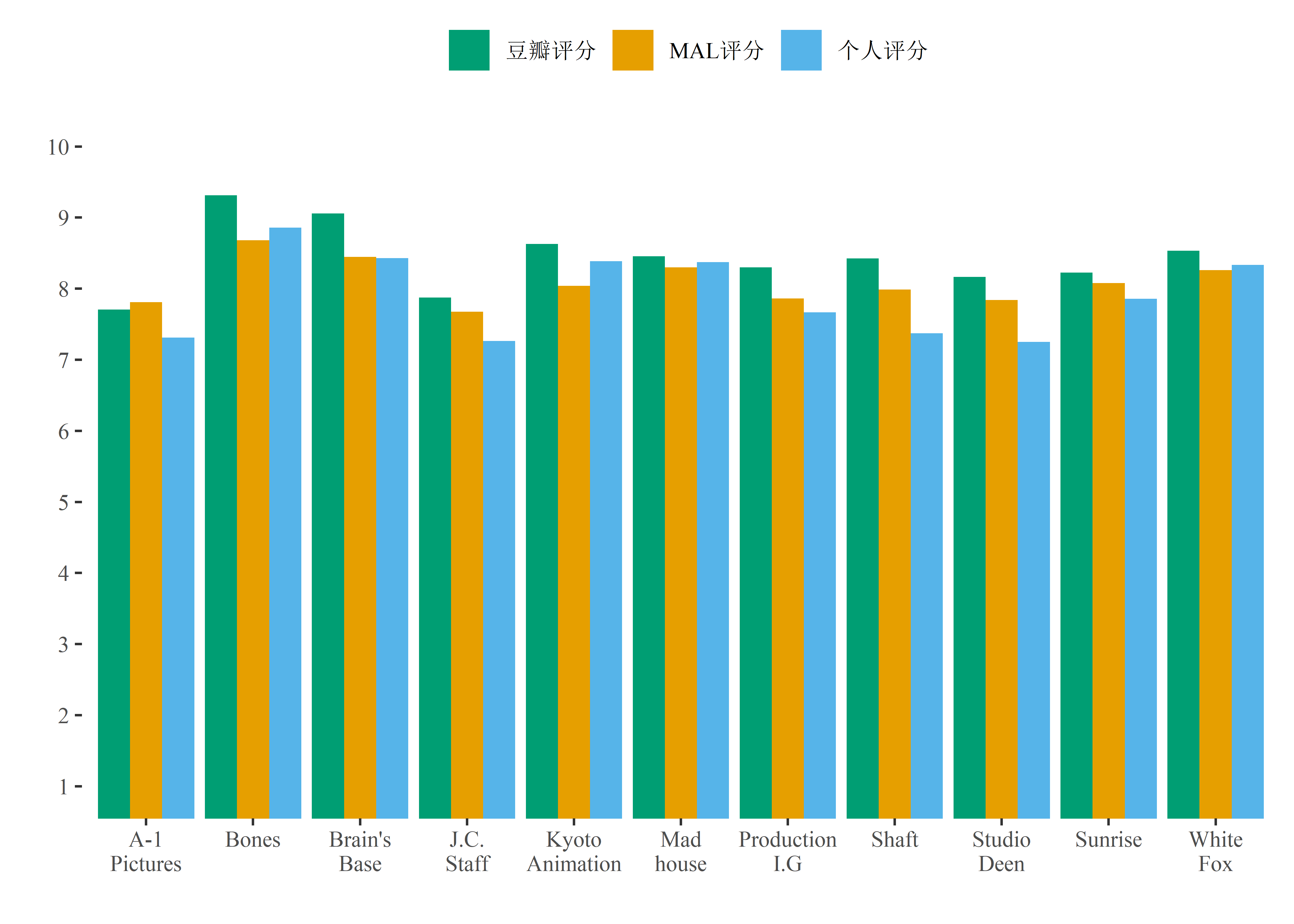
可以看到,骨头社(Bones)的评价是最高的,而节操社的评价是最低的。如果某个番剧是骨头社、京阿尼、疯房子(Mad House)或者白狐社(White Fox)制作的,我基本上就可以放心的观看了(我对这几个公司的评分都要高于MAL上的评分)。
同上,也计划将这一变量转换成稀疏矩阵,并去掉个数出现太少的制作公司。
b9.评分及人数
3个评分变量和2个人数变量都是数值型,其中我的个人评分是反应变量,就是最终想通过模型预测的变量,而另外4个变量之间会有较高的相关,考虑只使用其中1个变量。先看一下相关的情况:
corrplot(cor(anime[, 10:14], use = 'complete.obs'),
method = 'number', type = 'upper')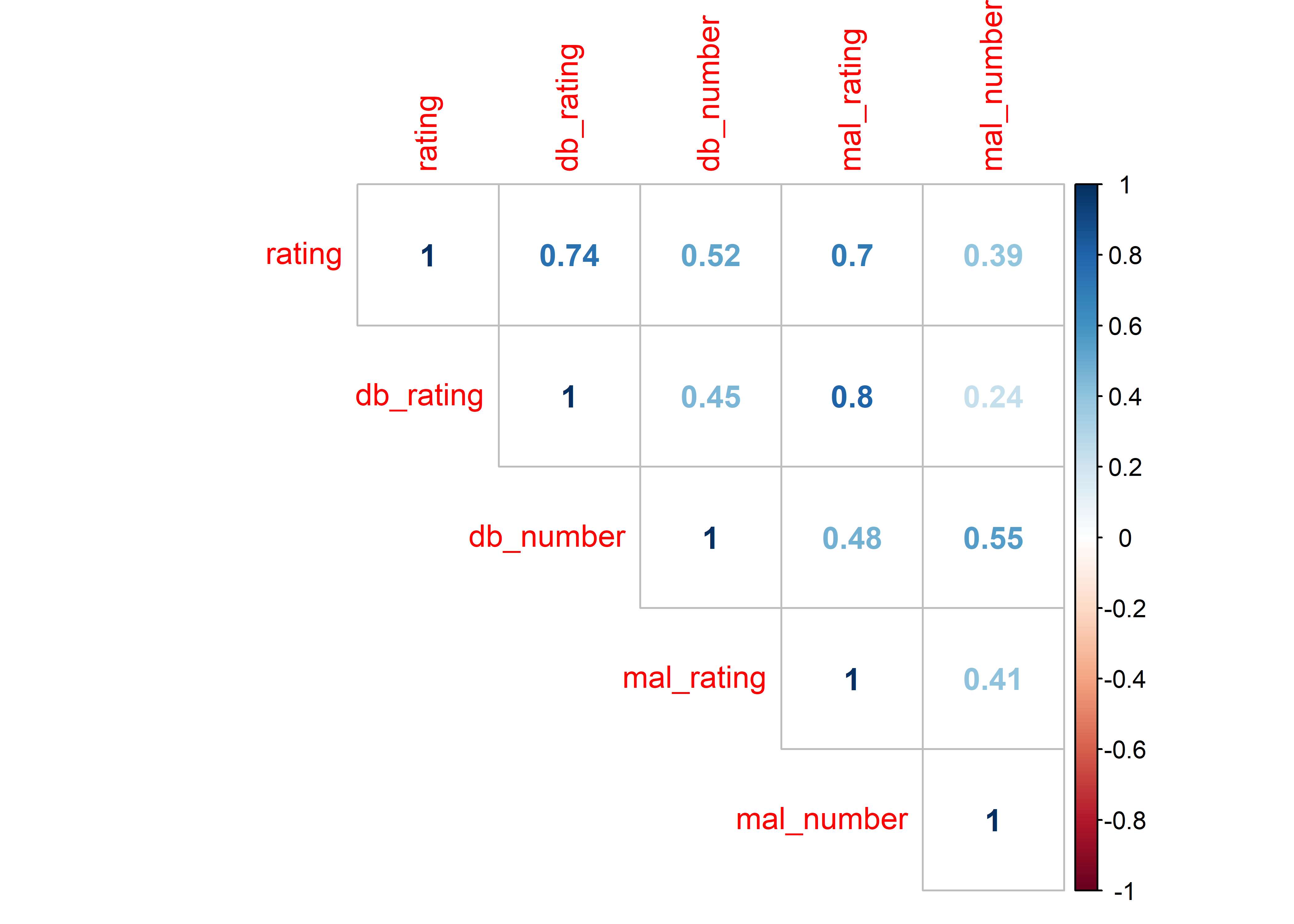
3个评分之间都由很高的相关,鉴于此,计划只使用豆瓣评分和MAL评分其中之一作为预测变量。在后面建模的时候,发现用豆瓣评分建立的模型不如使用MAL评分建立的模型要好,因此就只使用MAL的评分了,将其评分的中位数设为节点,大于中位数的视为推荐,小于中位数的视为不推荐。至于评分人数,跟我的评分相关也不低,但都低于相应的评分与我的评分之间的相关,因此就不使用了。对于我的评分,这次先处理为二元分类变量,将5-7分设为“不推荐”,而将8-10分设为“推荐”,作为反应变量的标签。
extra 1.个人、豆瓣与MAL的对比
虽然我个人的评分于豆瓣评分、MAL评分都有很高的相关,但还是有一定的差异的。首先来看看我心中最好的番剧(即我评为10分的番剧)和豆瓣上、MAL上最好的番剧有什么不同:
anime %>% filter(rating == 10) %>%
select(name, rating) %>%
bind_cols(anime %>% arrange(-db_rating) %>%
select(db_name = name, db_rating) %>% slice(1:10)) %>%
bind_cols(anime %>% arrange(-mal_rating) %>%
select(mal_name = name, mal_rating) %>% slice(1:10)) %>%
knitr::kable(digits = 2)| name | rating | db_name | db_rating | mal_name | mal_rating |
|---|---|---|---|---|---|
| 凉宫春日的忧郁 | 10 | 灵能百分百Ⅱ | 9.7 | 钢之炼金术师FA | 9.24 |
| 反叛的鲁路修 | 10 | 钢之炼金术师FA | 9.6 | 命运石之门 | 9.13 |
| 死亡笔记 | 10 | 夏目友人帐第三季 | 9.5 | 灵能百分百Ⅱ | 9.00 |
| 团子大家族 | 10 | 夏目友人帐第四季 | 9.5 | 团子大家族 第二季 | 8.99 |
| 反叛的鲁路修 R2 | 10 | 夏目友人帐第五季 | 9.5 | 反叛的鲁路修 R2 | 8.94 |
| 团子大家族 第二季 | 10 | 昭和元禄落语心中助六再临篇 | 9.5 | 来自深渊 | 8.87 |
| 钢之炼金术师FA | 10 | 夏目友人帐第六季 | 9.5 | 四月是你的谎言 | 8.86 |
| 凉宫春日的忧郁 2009 | 10 | 进击的巨人第三季1 | 9.5 | 昭和元禄落语心中助六再临篇 | 8.84 |
| 命运石之门 | 10 | 新世纪福音战士 | 9.4 | 反叛的鲁路修 | 8.77 |
| 一拳超人 | 10 | 夏目友人帐 第二季 | 9.4 | 物语系列第二季 | 8.77 |
可以看到,豆瓣上几乎是夏目的天下,跟我只重了钢炼FA一个。灵能2我也很喜欢,但感觉还是跟一拳超人差了一个档次。我的十佳跟MAL的十佳有5个重叠,对于物语系列能排到前10,甚感意外。
再来看看评分的整体分布:
anime %>% gather(rating, value, c('rating', 'db_rating', 'mal_rating')) %>%
select(rating, value) %>%
ggplot(aes(value, fill = rating)) +
geom_density(alpha = .8) +
scale_x_continuous(breaks = 4:10, labels = 4:10) +
scale_fill_manual(values = c('#009E73', '#E69F00', '#56B4E9'),
labels = c('豆瓣评分', 'MAL评分', '个人评分')) +
labs(x = '', y = '', fill = '') +
theme_tufte() +
theme(legend.position = 'top')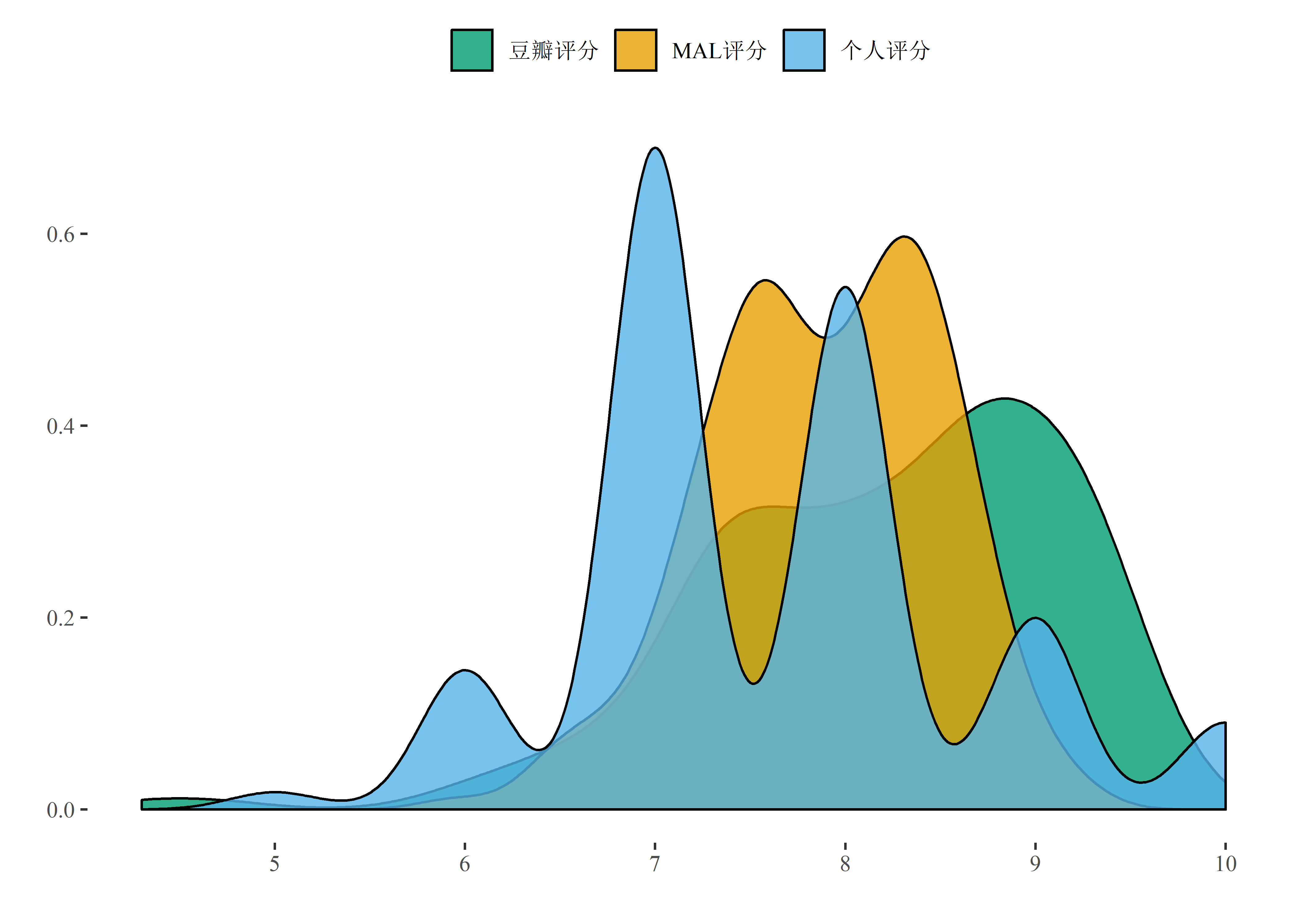
我的评分大部分都是7分或8分,7分就是那种看不看两可的感觉,而8分就是很值得一看了。MAL上的评分集中在7分和9分之间,很少有能在MAL上拿到9分以上的番剧;而豆瓣上的评分则稍微分散一些,峰值出现在9分左右,看来豆瓣上的用户倾向于给出高分,但这也是因为豆瓣上给番剧评分的用户远少于MAL上的用户:
anime %>% gather(number, value, c('db_number', 'mal_number')) %>%
select(number, value) %>%
ggplot(aes(value, fill = number)) +
geom_histogram(show.legend = FALSE) +
scale_x_continuous(labels = scales::comma) +
scale_fill_manual(values = c('#009E73', '#E69F00')) +
labs(x = '', y = '', fill = '') +
facet_wrap(~ number, nrow = 2, scales = 'free',
labeller = as_labeller(c('db_number' = '豆瓣人数',
'mal_number' = 'MAL人数'))) +
theme_tufte() +
theme(legend.position = 'top')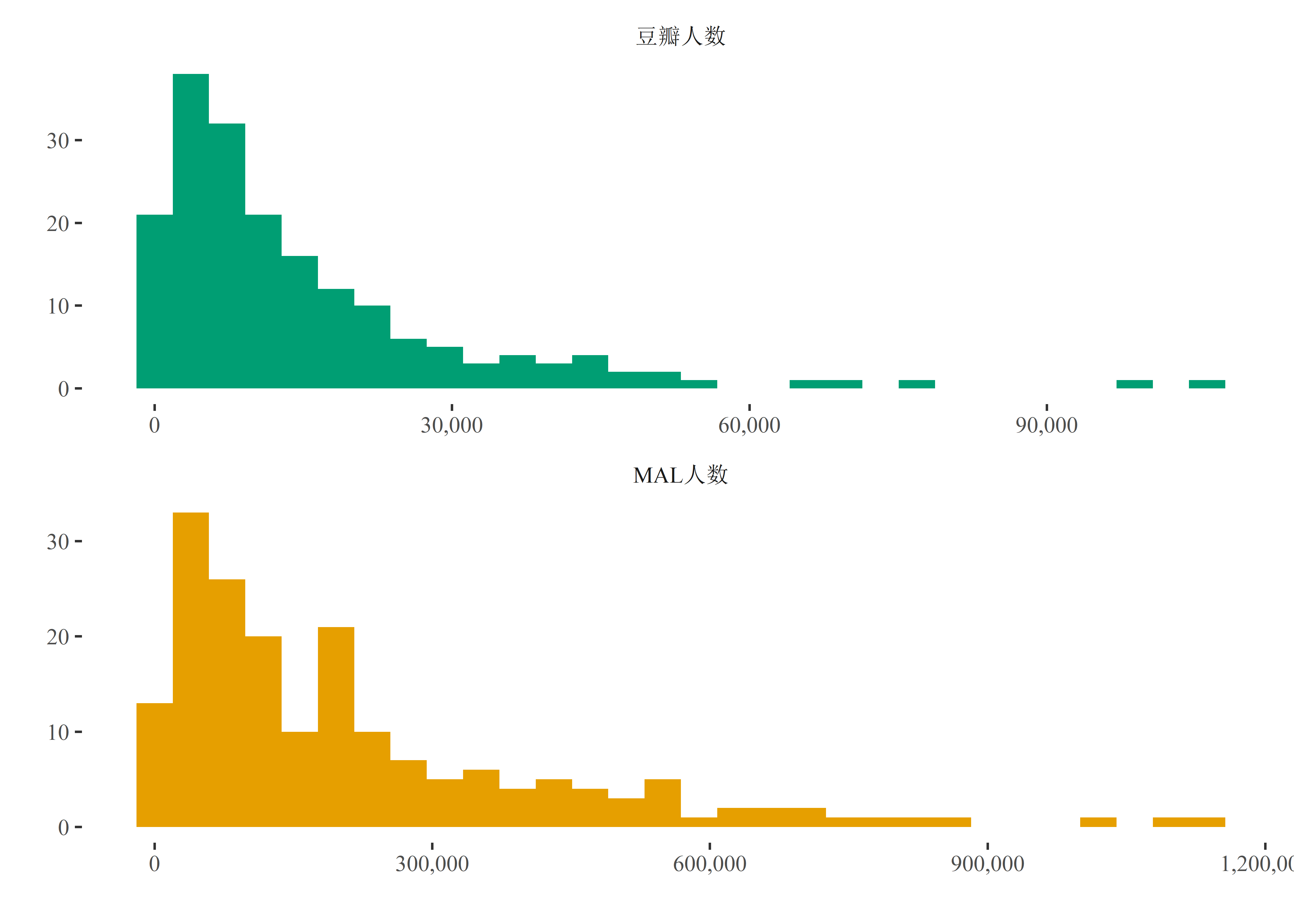
但从趋势上来看,还是差不多的。
b0.声优
最后一个变量是声优。虽然只收集了不到200个番剧,但声优数却有600多。先看一下主要声优的情况(仅统计参演超过10部的声优):
anime %>% separate_rows(cast, sep = '/') %>%
group_by(cast) %>%
my_awesome_summary() %>%
filter(N > 10) %>% arrange(-rating) %>%
knitr::kable(digits = 2)| cast | N | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|---|
| 关智一 | 12 | 8.75 | 9.06 | 27225.92 | 8.52 | 326825.7 |
| 浪川大辅 | 11 | 8.45 | 8.68 | 25943.91 | 8.28 | 323097.7 |
| 细谷佳正 | 12 | 8.42 | 8.97 | 27083.75 | 8.27 | 371816.4 |
| 大原沙耶香 | 11 | 8.36 | 8.75 | 21912.09 | 8.33 | 272202.0 |
| 小林优 | 13 | 8.31 | 8.69 | 21555.23 | 8.11 | 237782.9 |
| 石田彰 | 18 | 8.28 | 8.84 | 35076.67 | 8.27 | 151272.8 |
| 小山力也 | 11 | 8.09 | 8.40 | 20032.91 | 7.87 | 217325.6 |
| 三宅健太 | 12 | 8.08 | 8.27 | 20692.25 | 8.04 | 369599.2 |
| 神谷浩史 | 25 | 8.08 | 8.79 | 27032.56 | 8.27 | 239633.2 |
| 小野大辅 | 18 | 8.00 | 8.55 | 20281.28 | 7.89 | 213190.6 |
| 中村悠一 | 22 | 7.95 | 8.14 | 20212.82 | 7.92 | 298512.9 |
| 梶裕贵 | 25 | 7.92 | 8.50 | 20228.08 | 8.10 | 323644.1 |
| 樱井孝宏 | 20 | 7.90 | 8.48 | 22061.85 | 8.14 | 319606.4 |
| 中田让治 | 13 | 7.85 | 8.35 | 17024.69 | 7.96 | 229432.1 |
| 诹访部顺一 | 13 | 7.85 | 8.24 | 17122.31 | 7.84 | 163293.1 |
| 井上麻里奈 | 16 | 7.81 | 8.47 | 17329.00 | 7.96 | 317493.6 |
| 宫野真守 | 21 | 7.76 | 8.31 | 16738.55 | 8.01 | 338401.7 |
| 田村由加莉 | 12 | 7.75 | 8.16 | 16199.75 | 7.83 | 248854.1 |
| 植田佳奈 | 12 | 7.75 | 8.51 | 18014.50 | 8.05 | 239926.1 |
| 福山润 | 19 | 7.74 | 8.49 | 16092.37 | 8.13 | 253515.6 |
| 佐仓绫音 | 19 | 7.74 | 8.18 | 10453.89 | 7.87 | 194947.5 |
| 泽城美雪 | 25 | 7.72 | 8.35 | 18715.68 | 8.01 | 211165.4 |
| 新井里美 | 14 | 7.71 | 7.91 | 13257.64 | 7.70 | 209135.7 |
| 花泽香菜 | 25 | 7.68 | 8.26 | 15851.72 | 8.00 | 261241.5 |
| 伊藤静 | 12 | 7.67 | 8.38 | 13296.50 | 7.96 | 171365.3 |
| 早见沙织 | 14 | 7.64 | 8.24 | 20426.71 | 8.10 | 267863.5 |
| 川澄绫子 | 11 | 7.64 | 8.29 | 18295.00 | 7.93 | 196957.9 |
| 木村良平 | 11 | 7.64 | 8.31 | 19371.82 | 8.11 | 210926.9 |
| 下野纮 | 11 | 7.64 | 8.13 | 17083.45 | 7.87 | 239582.9 |
| 悠木碧 | 16 | 7.62 | 8.45 | 16303.12 | 8.07 | 357969.2 |
| 喜多村英梨 | 13 | 7.62 | 8.49 | 14083.85 | 8.18 | 339427.3 |
| 加藤英美里 | 12 | 7.58 | 8.04 | 11545.83 | 8.06 | 244129.2 |
| 松冈祯丞 | 12 | 7.58 | 8.25 | 15437.83 | 8.01 | 339119.0 |
| 逢坂良太 | 11 | 7.55 | 7.84 | 17280.18 | 7.86 | 277002.1 |
| 冈本信彦 | 15 | 7.53 | 8.19 | 16826.20 | 7.93 | 228771.8 |
| 杉田智和 | 21 | 7.52 | 8.23 | 13374.81 | 7.68 | 149927.9 |
| 能登麻美子 | 18 | 7.50 | 7.94 | 12636.78 | 7.83 | 197120.6 |
| 佐藤聪美 | 12 | 7.50 | 8.22 | 9852.75 | 7.81 | 166250.3 |
| 钉宫理惠 | 13 | 7.46 | 8.08 | 16001.85 | 7.80 | 303504.1 |
| 日笠阳子 | 11 | 7.45 | 8.40 | 13392.18 | 7.97 | 206685.2 |
| 堀江由衣 | 11 | 7.36 | 8.32 | 14453.00 | 8.10 | 281930.8 |
| 竹达彩奈 | 11 | 7.36 | 7.89 | 15388.18 | 7.66 | 340554.2 |
| 石川界人 | 14 | 7.29 | 7.66 | 10563.36 | 7.47 | 205135.0 |
| 茅野爱衣 | 14 | 7.21 | 8.05 | 18157.86 | 8.08 | 270272.0 |
| 井口裕香 | 15 | 7.07 | 7.81 | 8491.73 | 7.87 | 239696.8 |
关智一以绝对的优势排在了第一名,看来只要有他出演,质量就可以得到保证。那看看他出演了哪些番剧吧:
anime %>% filter(str_detect(cast, '关智一')) %>%
select(name, rating, db_rating, db_number, mal_rating, mal_number) %>%
knitr::kable(digits = 2)| name | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|
| 新世纪福音战士 | 8 | 9.4 | 69782 | 8.33 | 416593 |
| 青之文学 | 8 | 8.7 | 16481 | 7.82 | 40803 |
| 命运石之门 | 10 | 9.3 | 39302 | 9.13 | 653578 |
| 命运之夜前传 | 9 | 9.1 | 38651 | 8.42 | 426719 |
| 命运之夜前传第二期 | 9 | 9.1 | 30630 | 8.64 | 356533 |
| 心理测量者 | 8 | 8.8 | 26766 | 8.43 | 428052 |
| 命运之夜 无限剑制 | 8 | 8.6 | 20634 | 8.31 | 301393 |
| 命运之夜 无限剑制 第二季 | 8 | 8.3 | 13787 | 8.39 | 254243 |
| 一拳超人 | 10 | 9.3 | 45526 | 8.70 | 836549 |
| 昭和元禄落语心中 | 9 | 9.4 | 12574 | 8.62 | 55045 |
| 昭和元禄落语心中助六再临篇 | 9 | 9.5 | 4674 | 8.84 | 33790 |
| 命运石之门0 | 9 | 9.2 | 7904 | 8.59 | 118610 |
但我目前最喜欢的声优是神谷浩史,在我看的番剧中,他出现的次数也是最多的,来看看他的情况:
anime %>% filter(str_detect(cast, '神谷浩史')) %>%
select(name, rating, db_rating, db_number, mal_rating, mal_number) %>%
knitr::kable(digits = 2)| name | rating | db_rating | db_number | mal_rating | mal_number |
|---|---|---|---|---|---|
| 再见,绝望先生 | 8 | 8.5 | 14684 | 7.96 | 93182 |
| 夏目友人帐 | 9 | 9.3 | 106587 | 8.38 | 118354 |
| 夏目友人帐 第二季 | 9 | 9.4 | 64594 | 8.61 | 84469 |
| 化物语 | 8 | 8.6 | 22429 | 8.35 | 403140 |
| 无头骑士异闻录 | 8 | 8.7 | 38140 | 8.26 | 412301 |
| 天使的心跳 | 7 | 7.9 | 18793 | 8.28 | 714781 |
| 夏目友人帐第三季 | 9 | 9.5 | 51257 | 8.64 | 75891 |
| 伪物语 | 7 | 8.5 | 9086 | 8.20 | 246841 |
| 夏目友人帐第四季 | 9 | 9.5 | 43673 | 8.71 | 68662 |
| 猫物语(黑) | 7 | 8.6 | 6007 | 8.03 | 183539 |
| 进击的巨人 | 9 | 8.9 | 97544 | 8.47 | 1078647 |
| 物语系列第二季 | 7 | 9.1 | 4844 | 8.77 | 189502 |
| 命运之夜 无限剑制 | 8 | 8.6 | 20634 | 8.31 | 301393 |
| 七大罪 | 7 | 8.4 | 7072 | 8.23 | 497232 |
| 无头骑士异闻录 承 | 8 | 8.8 | 9448 | 8.09 | 151912 |
| 命运之夜 无限剑制 第二季 | 8 | 8.3 | 13787 | 8.39 | 254243 |
| 那就是声优 | 7 | 7.2 | 1290 | 7.08 | 13365 |
| 无头骑士异闻录 转 | 8 | 8.7 | 5982 | 8.08 | 115729 |
| 进击!巨人中学校 | 7 | 7.5 | 1283 | 7.06 | 45391 |
| 无头骑士异闻录 结 | 8 | 8.7 | 5040 | 8.17 | 99909 |
| 齐木楠雄的灾难 | 8 | 9.3 | 37064 | 8.55 | 109573 |
| 夏目友人帐第五季 | 9 | 9.5 | 26317 | 8.63 | 38075 |
| 进击的巨人第二季 | 9 | 9.2 | 31939 | 8.43 | 471478 |
| 夏目友人帐第六季 | 9 | 9.5 | 19896 | 8.71 | 31475 |
| 进击的巨人第三季1 | 9 | 9.5 | 18424 | 8.47 | 191745 |
卡米亚真是出演了不少热门番剧。
这一变量也是转换成稀疏矩阵,并去掉出现次数太少的声优。
extra 2.声优关系网络
这种图挺难画好看的,花了不少时间来调整:
anime %>% separate_rows(cast, sep = '/') %>%
group_by(name) %>%
mutate(linenumber = group_indices()) %>%
pairwise_count(cast, linenumber) %>%
group_by(item1, item2) %>%
count(sort = TRUE) %>%
ungroup() %>%
filter(n > 4) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(alpha = n, width = n), color = 'grey50') +
scale_edge_width(range = c(.5, 2)) +
geom_node_point(color = '#D55E00', size = 4) +
geom_node_text(aes(label = name), size = 2, color = 'black') +
theme_void() +
theme(legend.position = '')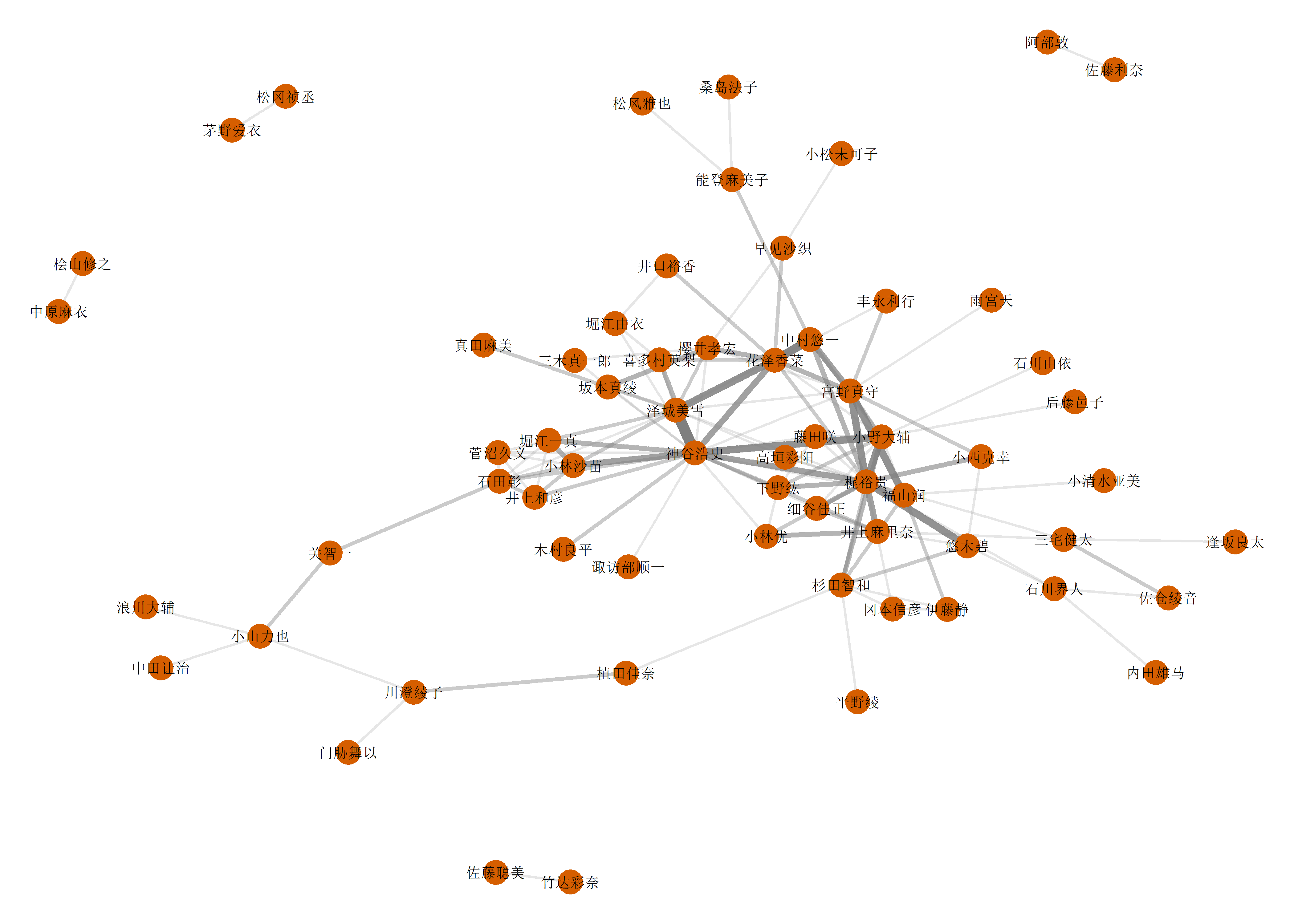
仔细看的话,可以看到不少有意思的地方,但这不是主题,略过。
C.建模与评估
数据都探索完了,接下来就可以建立模型,进行分类了。
c1.清洗数据
不过首先还是应该对数据进行清洗,需要清洗的地方前面以前都提到了:
anime_clean <- anime %>%
mutate(season_more = ifelse(series %in% (anime %>% filter(season_number > 1) %>%
pull(series) %>% unique()), 1, 0),
lengthy = ifelse(episode > 20, 1, 0),
old = ifelse(year < 2015, 1, 0),
mal_recommand = ifelse(mal_rating > median(mal_rating), 1, 0),
recommend = ifelse(rating > 7, 1, 0),
recommend = factor(recommend, levels = c(1, 0),
labels = c('recommend', 'not recommend'))) %>%
bind_cols(anime %>% mutate(row = row_number()) %>%
separate_rows(genra, sep = ',') %>%
cast_sparse(row, genra) %>%
as.matrix() %>%
as_tibble() %>%
select(which(colSums(.) > 9)),
anime %>% mutate(row = row_number()) %>%
cast_sparse(row, studio) %>%
as.matrix() %>%
as_tibble() %>%
select(which(colSums(.) > 4)),
anime %>% mutate(row = row_number()) %>%
separate_rows(cast, sep = '/') %>%
cast_sparse(row, cast) %>%
as.matrix() %>%
as_tibble() %>%
select(which(colSums(.) > 4))) %>%
select(recommend, everything()) %>%
select(-3:-16) %>%
mutate_if(is.numeric, factor, levels = c(0, 1), labels = c('No', 'Yes'))这大概是我接触R以来写的最长的一段数据清洗的代码了,tidyverse化的R代码,真是越看越好看。现在的数据共有182个变量:
dim(anime_clean)## [1] 186 182c2.创建训练数据集和测试数据集
然后将数据分为训练集和测试集,训练集包括124行数据,测试集包括剩余的62行数据:
set.seed(0509)
anime_train <- anime_clean %>% sample_n(124)
anime_test <- anime_clean %>% setdiff(anime_train)c3.朴素贝叶斯算法
先试试朴素贝叶斯算法:
anime_class <- naiveBayes(anime_train[, -1], anime_train$recommend)
anime_pred <- predict(anime_class, anime_test[, -1])
CrossTable(anime_pred, anime_test$recommend, prop.chisq = FALSE,
dnn = c('predicted', 'actual'))##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Row Total |
## | N / Col Total |
## | N / Table Total |
## |-------------------------|
##
##
## Total Observations in Table: 62
##
##
## | actual
## predicted | recommend | not recommend | Row Total |
## --------------|---------------|---------------|---------------|
## recommend | 28 | 3 | 31 |
## | 0.903 | 0.097 | 0.500 |
## | 0.800 | 0.111 | |
## | 0.452 | 0.048 | |
## --------------|---------------|---------------|---------------|
## not recommend | 7 | 24 | 31 |
## | 0.226 | 0.774 | 0.500 |
## | 0.200 | 0.889 | |
## | 0.113 | 0.387 | |
## --------------|---------------|---------------|---------------|
## Column Total | 35 | 27 | 62 |
## | 0.565 | 0.435 | |
## --------------|---------------|---------------|---------------|
##
## 结果似乎还不错,有3个不推荐的分类为了推荐,另有7个推荐的分类为了不推荐。比起错过好番,我更怕遇到烂番,因为我稍微有些强迫症,一旦看了某个番剧,就会把它坚持看完,哪怕它再烂。看看是哪些番剧分类错了吧:
anime_test %>% bind_cols(predict = anime_pred) %>%
select(name, recommend, predict) %>%
filter(recommend != predict) %>%
knitr::kable(digits = 2)| name | recommend | predict |
|---|---|---|
| 再见,绝望先生 | recommend | not recommend |
| 我的妹妹不可能那么可爱 | recommend | not recommend |
| 我的妹妹不可能那么可爱第二季 | recommend | not recommend |
| 甲铁城的卡巴内瑞 | not recommend | recommend |
| 齐木楠雄的灾难 | recommend | not recommend |
| 暗杀教室Q | not recommend | recommend |
| 擅长捉弄的高木同学 | recommend | not recommend |
| 卫宫家今天的饭 | not recommend | recommend |
| MegaloBox | recommend | not recommend |
| 千绪的通学路 | recommend | not recommend |
暗杀教室Q作为暗杀教室的衍生剧,其实还蛮好看的,我评分的时候其实也在犹豫。有几个错的挺离谱的,比如MegaloBox,那真是强烈推荐啊;而甲铁城的卡巴内瑞,那真是强烈不推荐啊!
c4.规则学习算法
再试试规则学习算法:
anime_JRip <- JRip(recommend ~ ., data = anime_train[, -2])
anime_pred <- predict(anime_JRip, anime_test[, -1:-2])
CrossTable(anime_pred, anime_test$recommend, prop.chisq = FALSE,
dnn = c('predicted', 'actual'))##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Row Total |
## | N / Col Total |
## | N / Table Total |
## |-------------------------|
##
##
## Total Observations in Table: 62
##
##
## | actual
## predicted | recommend | not recommend | Row Total |
## --------------|---------------|---------------|---------------|
## recommend | 29 | 3 | 32 |
## | 0.906 | 0.094 | 0.516 |
## | 0.829 | 0.111 | |
## | 0.468 | 0.048 | |
## --------------|---------------|---------------|---------------|
## not recommend | 6 | 24 | 30 |
## | 0.200 | 0.800 | 0.484 |
## | 0.171 | 0.889 | |
## | 0.097 | 0.387 | |
## --------------|---------------|---------------|---------------|
## Column Total | 35 | 27 | 62 |
## | 0.565 | 0.435 | |
## --------------|---------------|---------------|---------------|
##
## 结果跟朴素贝叶斯算法差不多,只是在FN上少了1个。看下在规则学习算法下,哪些番剧被分类错了吧:
anime_test %>% bind_cols(predict = anime_pred) %>%
select(name, recommend, predict) %>%
filter(recommend != predict) %>%
knitr::kable(digits = 2)| name | recommend | predict |
|---|---|---|
| 轻音少女 第二季 | not recommend | recommend |
| 我的妹妹不可能那么可爱 | recommend | not recommend |
| 我的妹妹不可能那么可爱第二季 | recommend | not recommend |
| 游戏人生 | not recommend | recommend |
| 东京喰种 | not recommend | recommend |
| 刀剑神域Ⅱ | recommend | not recommend |
| 擅长捉弄的高木同学 | recommend | not recommend |
| 工作细胞 | recommend | not recommend |
| 千绪的通学路 | recommend | not recommend |
有4个番剧,两种算法都分类错了,看来应该找找原因,但是对于俺妹系列,我似乎应该把对它们的评分改了。另外,这一算法的一个严重错误是对工作细胞的分类,这么火的番剧,怎么可能不推荐呢?
D.局限与展望
第一次尝试就到此为止了,存在很多问题,比如,对于某些变量,我只是将其变为了二元分类变量,损失了很多信息。后面考虑使用决策树和随机森林等算法重新进行分类,并且打算再花些时间,建立一个验证数据集,收集30个左右我没有看过的番剧,看一看真实的效果如何。
这篇博客就到此为止了,这是我花时间最多的一篇博客了。
sessionInfo()## R version 3.5.3 (2019-03-11)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 17134)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Chinese (Simplified)_China.936
## [2] LC_CTYPE=Chinese (Simplified)_China.936
## [3] LC_MONETARY=Chinese (Simplified)_China.936
## [4] LC_NUMERIC=C
## [5] LC_TIME=Chinese (Simplified)_China.936
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] gmodels_2.18.1 RWeka_0.4-40 e1071_1.7-1 ggraph_1.0.2
## [5] igraph_1.2.4 widyr_0.1.1 tidytext_0.2.0 corrplot_0.84
## [9] ggthemes_4.1.1 here_0.1 readxl_1.3.1 forcats_0.4.0
## [13] stringr_1.4.0 dplyr_0.8.0.1 purrr_0.3.2 readr_1.3.1
## [17] tidyr_0.8.3 tibble_2.1.1 ggplot2_3.1.0 tidyverse_1.2.1
##
## loaded via a namespace (and not attached):
## [1] viridis_0.5.1 httr_1.4.0 jsonlite_1.6
## [4] viridisLite_0.3.0 modelr_0.1.4 gtools_3.8.1
## [7] assertthat_0.2.1 highr_0.8 cellranger_1.1.0
## [10] yaml_2.2.0 ggrepel_0.8.0 pillar_1.3.1
## [13] backports_1.1.3 lattice_0.20-38 glue_1.3.1
## [16] digest_0.6.18 polyclip_1.10-0 rvest_0.3.2
## [19] colorspace_1.4-1 htmltools_0.3.6 Matrix_1.2-15
## [22] plyr_1.8.4 pkgconfig_2.0.2 broom_0.5.1
## [25] haven_2.1.0 bookdown_0.9 scales_1.0.0
## [28] gdata_2.18.0 tweenr_1.0.1 ggforce_0.2.1
## [31] generics_0.0.2 farver_1.1.0 withr_2.1.2
## [34] lazyeval_0.2.2 cli_1.1.0 magrittr_1.5
## [37] crayon_1.3.4 evaluate_0.13 tokenizers_0.2.1
## [40] janeaustenr_0.1.5 fansi_0.4.0 nlme_3.1-137
## [43] SnowballC_0.6.0 MASS_7.3-51.1 xml2_1.2.0
## [46] class_7.3-15 blogdown_0.11 tools_3.5.3
## [49] RWekajars_3.9.3-1 hms_0.4.2 munsell_0.5.0
## [52] compiler_3.5.3 rlang_0.3.3 grid_3.5.3
## [55] rstudioapi_0.10 labeling_0.3 rmarkdown_1.12
## [58] gtable_0.3.0 R6_2.4.0 gridExtra_2.3
## [61] lubridate_1.7.4 knitr_1.22 utf8_1.1.4
## [64] rprojroot_1.3-2 rJava_0.9-11 stringi_1.4.3
## [67] Rcpp_1.0.1 tidyselect_0.2.5 xfun_0.6
