
利用文本分析对比两版本天龙八部
今年三月份,为了掌握文本分析技术,特意找了两个版本《天龙八部》的txt文件作为数据而进行练习,但可能被其他事情给耽搁了,当时只完成了一部分。前几天金老去世,令人不胜感概,于是想把这个《天龙八部》的文本分析完成,也算是以自己的方式表达对大师的怀念。
首先还是载入相关的包,这次的包有点多:
library(tidyverse)
library(readxl)
library(tidytext)
library(jiebaR)
library(ggthemes)
library(widyr)
library(igraph)
library(ggraph)然后将两个版本的小说文本导入,顺便导入了主要人物的人名,因为这次分析是以分析主要人物为主:
tl_new <- read_lines('tl_new.txt')
tl_old <- read_lines('tl_old.txt')
tl_main <- read_lines('tl_main.txt') %>% .[-1]因为每个人的称呼不止一个,如乔帮主、萧大王、姊夫等等,都是指萧峰一个人,所以为了统一人名,还要做一些替换工作:
tl_new_tran <- tl_new %>%
str_replace_all('(段公子)|(哥哥)|(誉儿)', '段誉') %>%
str_replace_all('(乔峰)|(乔帮主)|(姊夫)|(萧大王)', '萧峰') %>%
str_replace_all('(梦郎)|(小和尚)', '虚竹') %>%
str_replace_all('(南海鳄神)|(岳老二)', '岳老三') %>%
str_replace_all('带头大哥', '玄慈') %>%
str_replace_all('延庆太子', '段延庆') %>%
str_replace_all('白长老', '白世镜') %>%
str_replace_all('全舵主', '全冠清') %>%
str_replace_all('甘宝宝', '钟夫人') %>%
str_replace_all('小康', '马夫人') %>%
str_replace_all('灵儿', '钟灵') %>%
str_replace_all('(星宿老怪)|(星宿老仙)', '丁春秋') %>%
str_replace_all('庄聚贤', '游坦之') %>%
str_replace_all('(慕容公子)|(表哥)', '慕容复') %>%
str_replace_all('国师', '鸠摩智') %>%
str_replace_all('表妹', '王语嫣') %>%
str_replace_all('(婉妹)|(木姊姊)', '木婉清') %>%
str_replace_all('(郡主)|(小师妹)', '阿紫') %>%
str_replace_all('段王爷', '段正淳')
tl_old_tran <- tl_old %>%
str_replace_all('(段公子)|(哥哥)|(誉儿)', '段誉') %>%
str_replace_all('(乔峰)|(乔帮主)|(姊夫)|(萧大王)', '萧峰') %>%
str_replace_all('(梦郎)|(小和尚)', '虚竹') %>%
str_replace_all('(南海鳄神)|(岳老二)', '岳老三') %>%
str_replace_all('带头大哥', '玄慈') %>%
str_replace_all('延庆太子', '段延庆') %>%
str_replace_all('白长老', '白世镜') %>%
str_replace_all('全舵主', '全冠清') %>%
str_replace_all('甘宝宝', '钟夫人') %>%
str_replace_all('小康', '马夫人') %>%
str_replace_all('灵儿', '钟灵') %>%
str_replace_all('(星宿老怪)|(星宿老仙)', '丁春秋') %>%
str_replace_all('庄聚贤', '游坦之') %>%
str_replace_all('(慕容公子)|(表哥)', '慕容复') %>%
str_replace_all('国师', '鸠摩智') %>%
str_replace_all('表妹', '王语嫣') %>%
str_replace_all('(婉妹)|(木姊姊)', '木婉清') %>%
str_replace_all('(郡主)|(小师妹)', '阿紫') %>%
str_replace_all('段王爷', '段正淳')上面的替换工作并不全,比如,同样是段郞,有时可能是指段誉,有时可能是指段正淳,这就需要具体的情境,才能判断出来这个词指的是谁,但这个工作太麻烦了,这里就放弃了。
下面创建分词环境,并把主要人物的人名添加进了自定义词库,然后针对两个版本分别进行分词:
worker <- worker(stop_word = 'stopwords_cn.txt', user = 'tl_main.txt')
tl_word_new <- worker[tl_new_tran]
tl_word_old <- worker[tl_old_tran]再分别做一些简单的清洗工作:
tl_freq_new <- tl_word_new %>%
table() %>%
as.tibble() %>%
select(word = 1, freq = 2) %>%
filter(!str_detect(word, '(\\d+)|([A-Za-z]+)|(\\s+)')) %>%
filter(str_length(word) > 1) %>%
arrange(-freq) %>%
filter(freq > 100)
tl_freq_old <- tl_word_old %>%
table() %>%
as.tibble() %>%
select(word = 1, freq = 2) %>%
filter(!str_detect(word, '(\\d+)|([A-Za-z]+)|(\\s+)')) %>%
filter(str_length(word) > 1) %>%
arrange(-freq) %>%
filter(freq > 100)然后就可以开始画图并进行分析了。
主要人物出现频次对比
首先假设,一个人物越重要,他的名字在书中出现的次数就越多(我似乎应该反过来说),后续的分析都是建立在这一假设之上的,但还是要再整理一下数据。首先把主要人物的名字从所有的词汇中挑选出来,再根据两个版本不同的字数做一些调整,最后再把两个版本的数据合并起来:
tl_freq_main_new <- tl_freq_new %>%
filter(word %in% tl_main) %>%
mutate(version = 'new')
tl_freq_main_old <- tl_freq_old %>%
filter(word %in% tl_main) %>%
mutate(version = 'old', freq = round(freq*6.42/6.27))
tl_freq_com <- bind_rows(tl_freq_main_old, tl_freq_main_new) %>%
mutate(order = row_number(),
version = fct_relevel(version, c('old', 'new')))然后就可以绘图了:
tl_freq_com %>% ggplot(aes(order, freq)) +
geom_col(fill = '#870204', width = .8) +
geom_text(aes(label = freq),
nudge_y = ifelse(str_length(tl_freq_com$freq) > 3, -120, -80),
size = 2, color = 'white') +
coord_flip() +
scale_x_reverse(breaks = tl_freq_com$order,
labels = tl_freq_com$word,
expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0)) +
labs(x = '人 物', y = '频 次') +
facet_wrap(~ version, scales = 'free_y',
labeller = as_labeller(c('old' = '旧 版', 'new' = '新 版'))) +
theme_tufte() +
theme(strip.text = element_text(size = 12))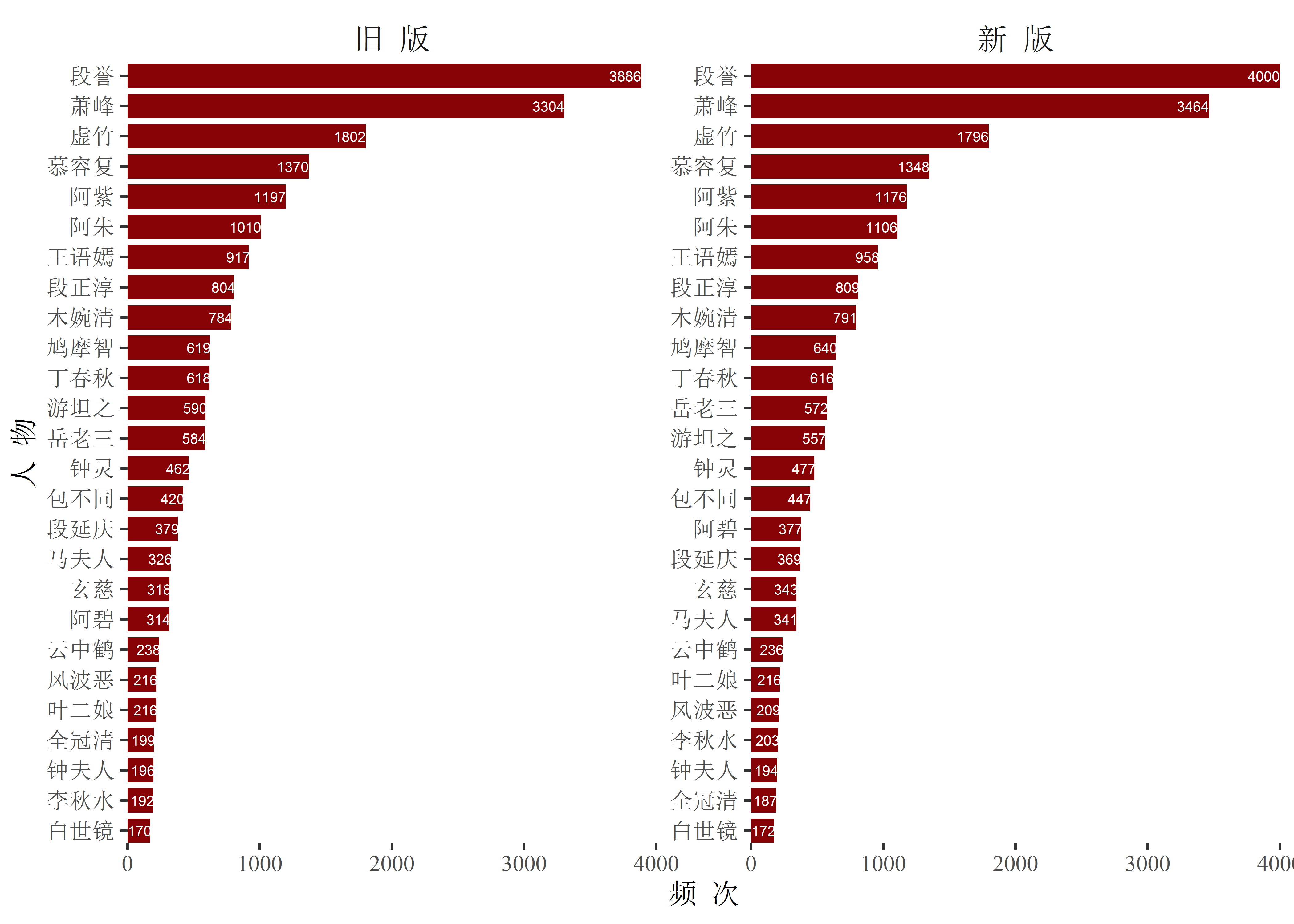
从这张图来看,两个版本可能没有太大的差异,三大男主角和三大女主角的地位没有变化,夹在他们中间的慕容复的位次也没有变化。不过,我一直以为王语嫣是女一号呢,没想到只排第三名。
为了更清楚地对比两个版本主要人物的出场次数的差异,我将两个版本每个人物的出场频次做了差,并重新汇了图:
tl_freq_com %>% select(-order) %>%
spread(version, freq) %>%
mutate(diff = new - old) %>%
ggplot(aes(fct_reorder(word, diff), diff)) +
geom_col(width = .8, fill = '#870204') +
scale_y_continuous(breaks = seq(-400, 300, 50), expand = c(0, 0)) +
labs(x = '名 字', y = '变 化') +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, vjust = .6, size = 10))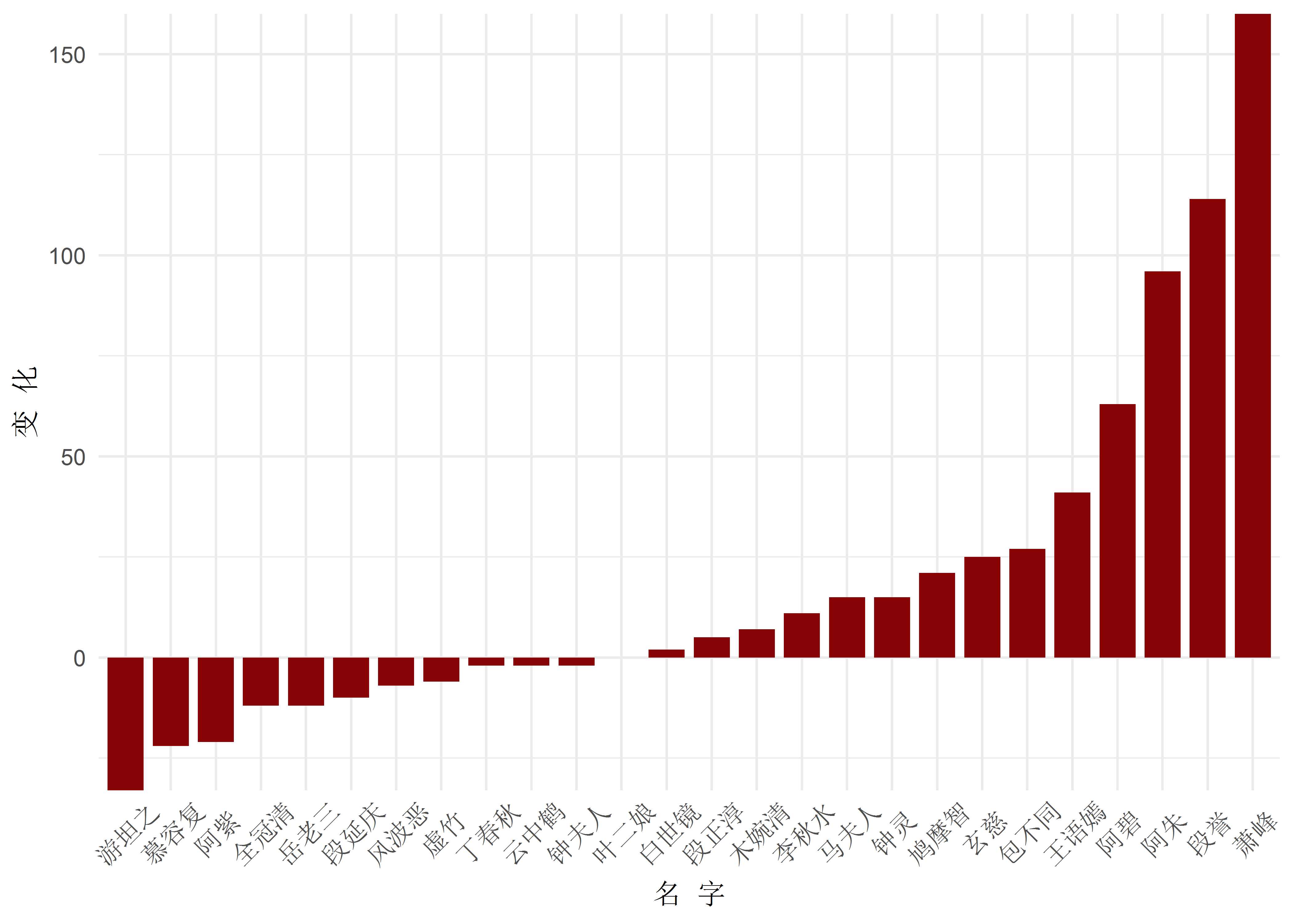
忘了说下,这里的差值是用新版本的频次减去了旧版本的频次。从这张图来看就很明显了,新版本中,游坦之、阿紫和慕容复的出现有所下降,而萧峰、段誉和阿朱的出场频次有了很大幅度的增加,这主要因为新版本加了很多阿朱和萧峰的内容。虽然阿紫和阿朱两姐妹出场的频次此消彼长,但阿紫女一号的地位并没有被撼动。
下面分章节来对比各主角的出场情况。
主角在不同章节出现频次对比
首先还是要整理一下数据,并把两个版本的数据合并起来,这里我将出场频次前七的角色视为主角,这七人分别是段誉、萧峰、虚竹、慕容复、阿紫、阿朱和王语嫣:
tl_chapter_new <- tl_word_new %>%
as.tibble() %>%
mutate(chapter = cumsum(str_detect(value, '^\\d{1,2}$')))
tl_chapter_old <- tl_word_old %>%
as.tibble() %>%
mutate(chapter = cumsum(str_detect(value, '^\\d{1,2}$')))
tl_chapter_lead_new <- tl_chapter_new %>%
count(chapter, value) %>%
filter(value %in% tl_freq_main_new$word[1:7]) %>%
mutate(version = 'new')
tl_chapter_lead_old <- tl_chapter_old %>%
count(chapter, value) %>%
filter(value %in% tl_freq_main_old$word[1:7]) %>%
mutate(version = 'old')
tl_chapter_lead_com <- bind_rows(tl_chapter_lead_new, tl_chapter_lead_old) %>%
filter(chapter != 0)然后进行绘图:
tl_chapter_lead_com %>% ggplot(aes(factor(chapter), n)) +
geom_line(aes(group = value, color = value), size = 1.2) +
facet_wrap(~ version, nrow = 2,
labeller = as_labeller(c('old' = '旧 版', 'new' = '新 版'))) +
scale_color_brewer(palette = 'Set1') +
labs(x = '章 节', y = '频 次', color = '人 物') +
theme_minimal() +
theme(strip.text = element_text(size = 12),
legend.position = 'bottom',
axis.text.x = element_text(size = 8, angle = 45)) +
guides(color = guide_legend(nrow = 1))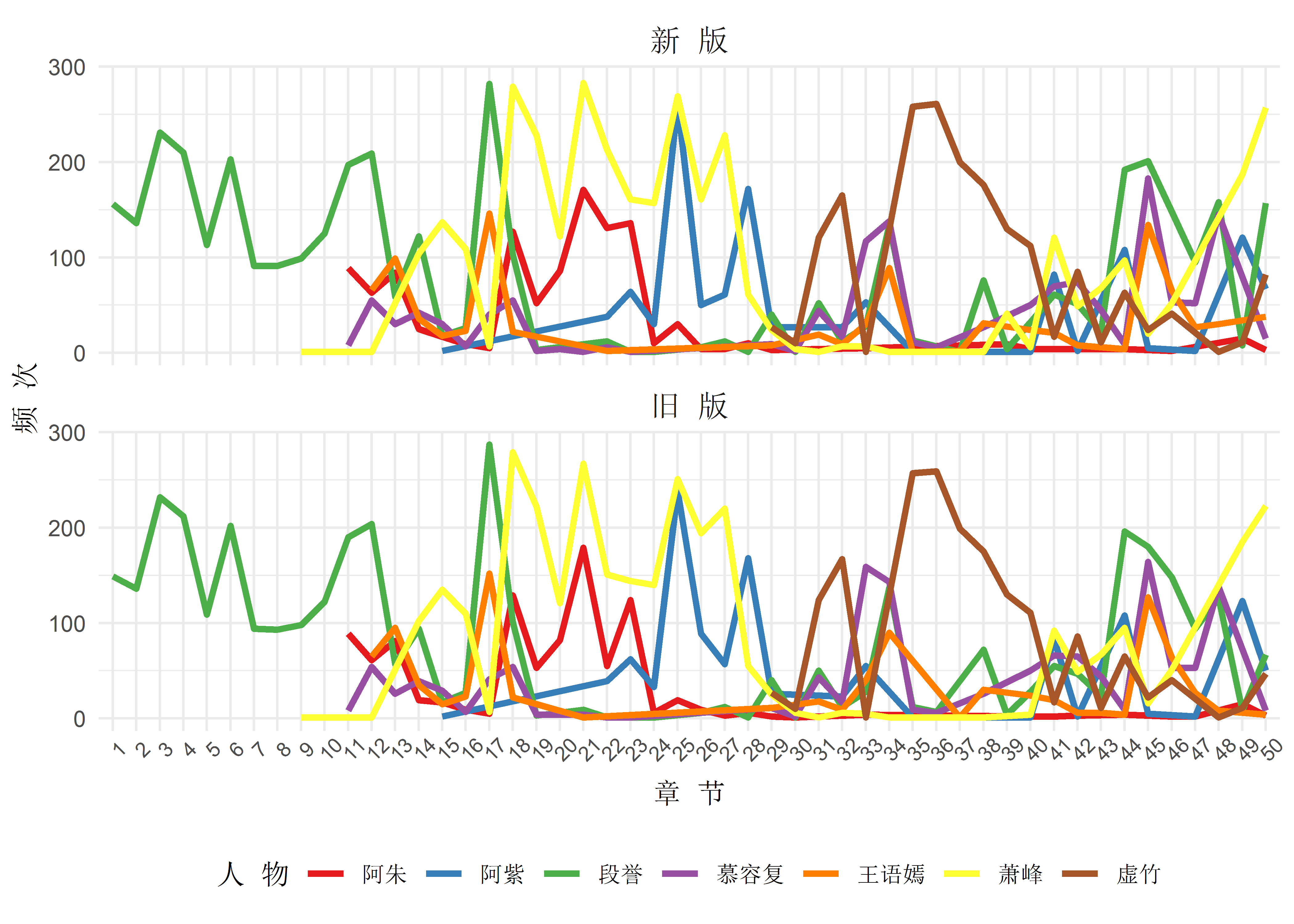
图有点乱,但我也没想到更好的呈现方式。七位主角在两个版本各章节的出场趋势大体上相同,只有某些章节存在差异:新版的第22章,阿朱和萧峰有了更多的出场,应该是加了更多描写他俩感情的内容,而新版的第26章,阿紫和萧峰的出场都有所减少,不知道删掉了什么内容;另外,对比下阿朱阿紫两姐妹,虽然阿紫总出场频次高于姐姐,但她共计出场了30多章,而阿朱只出场了10多章,所以要算下频次章节比的话,阿朱才是女一号。其他几位主角也多少有些变化,但先略过不提。下面进行最重要的情感分析。
情感分析
首先还是要整理、合并数据:
sentiment <- read_xlsx('情感词汇本体.xlsx') %>%
select(word = 1, sentiment = 7) %>%
filter(sentiment == 1 | sentiment == 2) %>%
mutate(sentiment = ifelse(sentiment > 1, -1, 1))
tl_sentiment_new <- tl_chapter_new %>%
left_join(sentiment, by = c('value' = 'word')) %>%
filter(!chapter %in% c(0, 51), !is.na(sentiment)) %>%
group_by(chapter) %>%
summarise(sentiment = sum(sentiment)) %>%
mutate(version = 'new')
tl_sentiment_old <- tl_chapter_old %>%
left_join(sentiment, by = c('value' = 'word')) %>%
filter(!chapter %in% c(0, 51), !is.na(sentiment)) %>%
group_by(chapter) %>%
summarise(sentiment = sum(sentiment)) %>%
mutate(version = 'old')
tl_sentiment_com <- bind_rows(tl_sentiment_new, tl_sentiment_old)然后绘图,这次应该比较容易看出差异:
tl_sentiment_com %>% ggplot(aes(factor(chapter), sentiment)) +
geom_line(aes(group = version, color = version), size = 1.2) +
labs(x = '章 节', y = '分 数', color = '版本') +
scale_y_continuous(breaks = seq(-100, 300, 50)) +
scale_color_brewer(palette = 'Set1', labels = c('新版', '旧版')) +
theme_minimal() +
theme(legend.position = 'top',
axis.text.x = element_text(size = 8, angle = 45))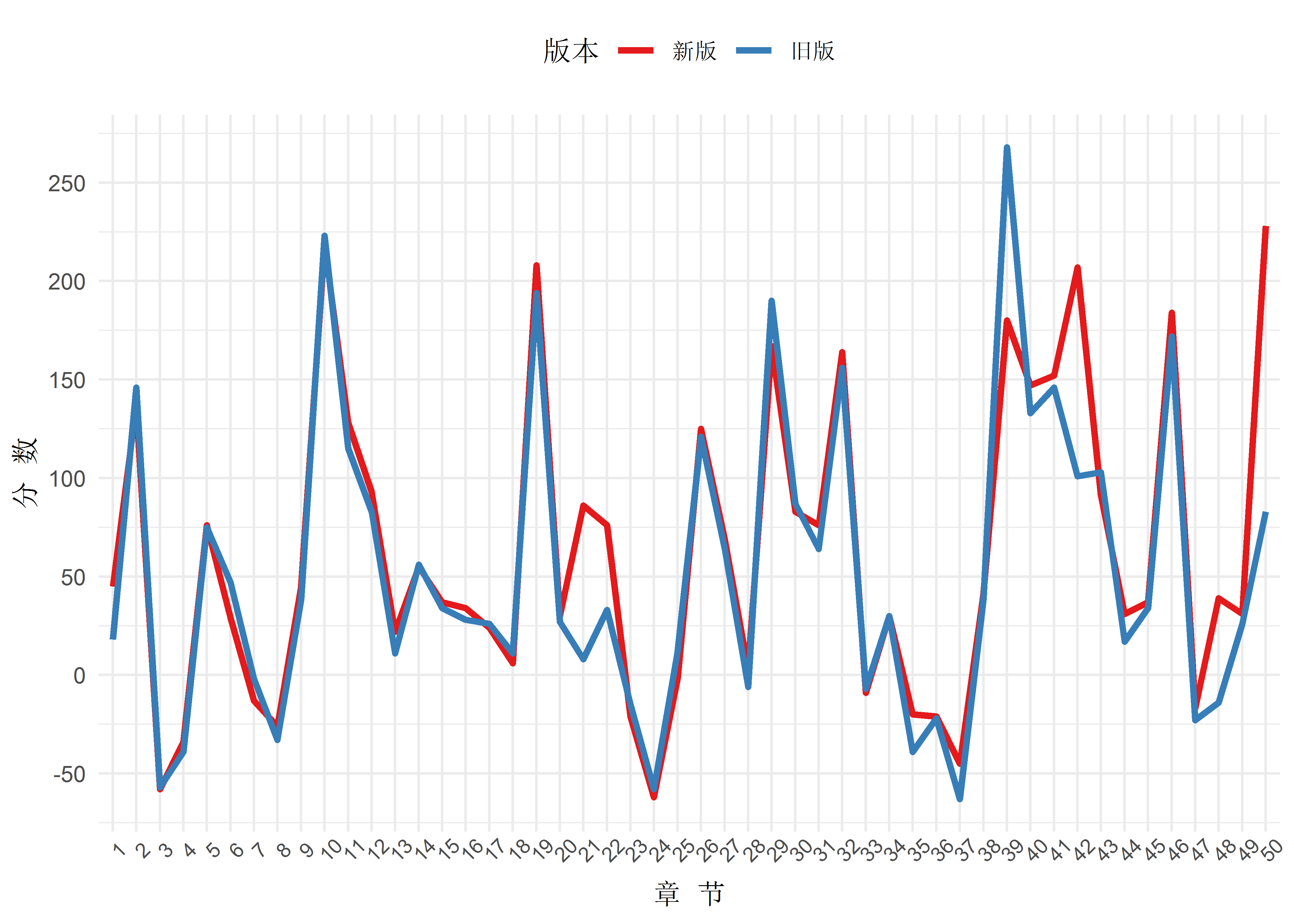
第一个差异出现在21章和22章,新版的情感更积极一些,这应该更能加深随后的阿朱之死所带来的悲痛;第二个差异出现在39章,好像是灵鹫宫大战之后,旧版中这一章是整部小说情感最积极之处,但在新版中却有所弱化;第三个差异是第42章,少林寺大战,我不知道这部分两个版本有什么具体的差异(实际上我并没有看过新版),但新版这里更积极一点;最后一个差异出现在最后一章,虽然新版中并没有改变萧峰最后的命运,但这一章却成了新版中情感最积极的一章。
分析就到此结束了,最后在画个主要人物的关系网吧。
主要人物关系网
这个关系网在两个版本之间可能不会存在什么差异,所以就只用新版画了。首先还是处理下数据:
tl_relation_new <- tibble(hero1 = rep(tl_main, each = length(tl_main)),
hero2 = rep(tl_main, length(tl_main))) %>%
filter(hero1 != hero2)
tl_chapter_main_new <- tl_chapter_new %>%
filter(value %in% tl_main) %>%
distinct()
tl_network_new <- tibble()
for (i in 1:50) {
temp <- tibble(hero1 = rep(filter(tl_chapter_main_new, chapter == i)$value,
each = nrow(filter(tl_chapter_main_new, chapter == i))),
hero2 = rep(filter(tl_chapter_main_new, chapter == i)$value,
nrow(filter(tl_chapter_main_new, chapter == i)))) %>%
filter(hero1 != hero2)
tl_network_new <- bind_rows(tl_network_new, temp)
}
tl_network_main_new <- count(tl_network_new, hero1, hero2) %>%
arrange(-n)然后作图:
tl_network_main_new %>%
filter(n > 7) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour = "grey") +
geom_node_point(color = "steelblue", size = 8) +
geom_node_text(aes(label = name), vjust = 2.2, size = 3) +
theme_void() +
theme(legend.position = '')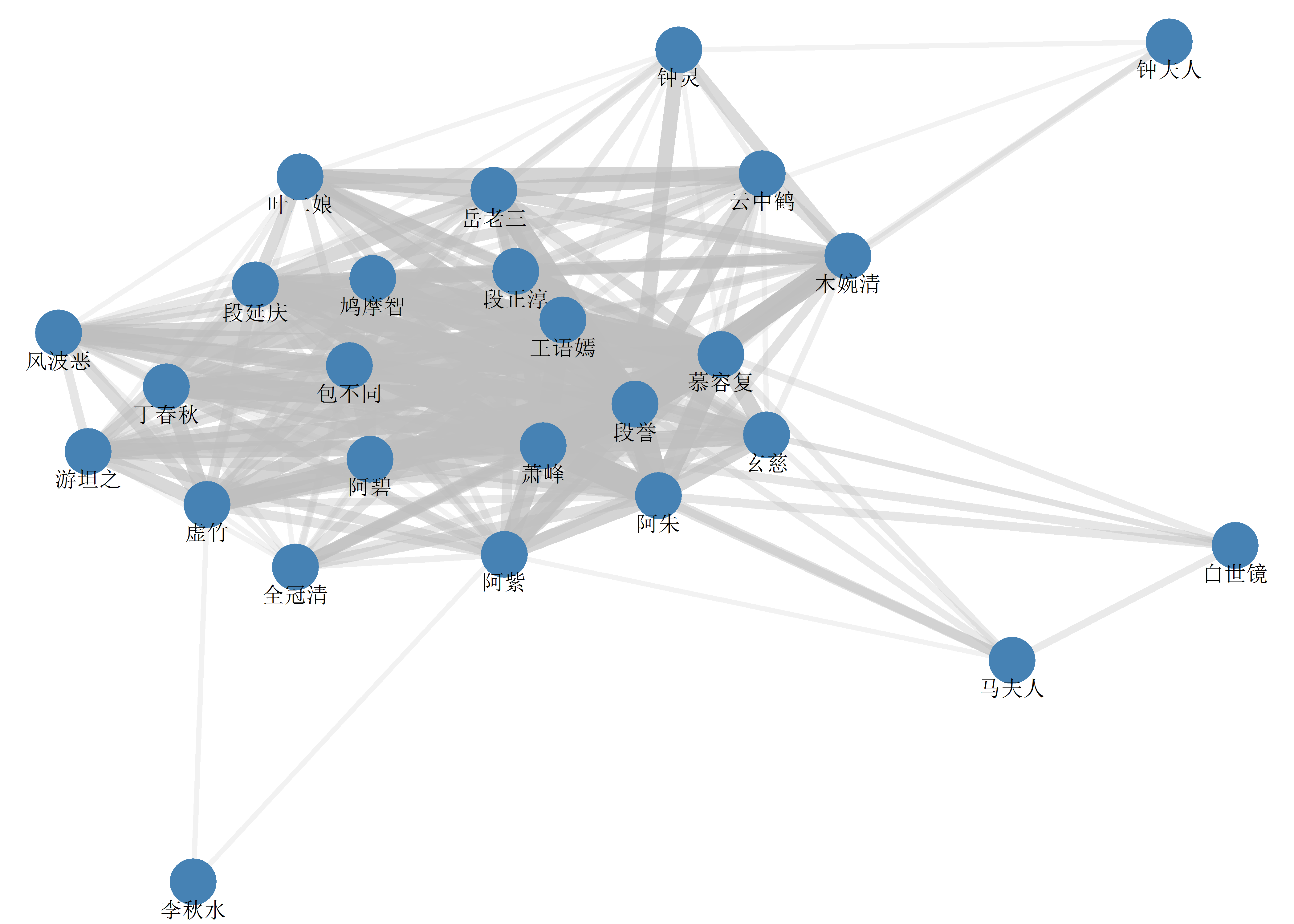
因为人物关系实在复杂,这里略去了一些不太重要的关系。这篇文章也就到此结束了。虽然很想写得更细一点,但时间实在有限,待以后有时间再慢慢填充内容吧。
sessionInfo()## R version 3.5.1 (2018-07-02)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 7 x64 (build 7601) Service Pack 1
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Chinese (Simplified)_People's Republic of China.936
## [2] LC_CTYPE=Chinese (Simplified)_People's Republic of China.936
## [3] LC_MONETARY=Chinese (Simplified)_People's Republic of China.936
## [4] LC_NUMERIC=C
## [5] LC_TIME=Chinese (Simplified)_People's Republic of China.936
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] bindrcpp_0.2.2 ggraph_1.0.2 igraph_1.2.2 widyr_0.1.1
## [5] ggthemes_4.0.1 jiebaR_0.9.99 jiebaRD_0.1 tidytext_0.2.0
## [9] readxl_1.1.0 forcats_0.3.0 stringr_1.3.1 dplyr_0.7.7
## [13] purrr_0.2.5 readr_1.1.1 tidyr_0.8.1 tibble_1.4.2
## [17] ggplot2_3.1.0 tidyverse_1.2.1
##
## loaded via a namespace (and not attached):
## [1] ggrepel_0.8.0 Rcpp_0.12.19 lubridate_1.7.4
## [4] lattice_0.20-35 assertthat_0.2.0 rprojroot_1.3-2
## [7] digest_0.6.18 ggforce_0.1.3 R6_2.3.0
## [10] cellranger_1.1.0 plyr_1.8.4 backports_1.1.2
## [13] evaluate_0.12 httr_1.3.1 blogdown_0.9
## [16] pillar_1.3.0 rlang_0.3.0.1 lazyeval_0.2.1
## [19] rstudioapi_0.8 Matrix_1.2-14 rmarkdown_1.10
## [22] labeling_0.3 munsell_0.5.0 broom_0.5.0
## [25] compiler_3.5.1 janeaustenr_0.1.5 modelr_0.1.2
## [28] xfun_0.4 pkgconfig_2.0.2 htmltools_0.3.6
## [31] tidyselect_0.2.5 gridExtra_2.3 bookdown_0.7
## [34] viridisLite_0.3.0 crayon_1.3.4 withr_2.1.2
## [37] MASS_7.3-50 SnowballC_0.5.1 grid_3.5.1
## [40] nlme_3.1-137 jsonlite_1.5 gtable_0.2.0
## [43] magrittr_1.5 units_0.6-1 scales_1.0.0
## [46] tokenizers_0.2.1 cli_1.0.1 stringi_1.2.4
## [49] farver_1.0 viridis_0.5.1 xml2_1.2.0
## [52] RColorBrewer_1.1-2 tools_3.5.1 glue_1.3.0
## [55] tweenr_1.0.0 hms_0.4.2 yaml_2.2.0
## [58] colorspace_1.3-2 rvest_0.3.2 knitr_1.20
## [61] bindr_0.1.1 haven_1.1.2
