
日记文本分析:第一部分
据说希腊的德尔菲神庙上刻着几条箴言,其中一条告诫我们要“认识你自己”。这条箴言刻起来容易,做起来却很难,甚至可能是人生最困难的事情之一。要想认识自己,大概有四种方法,一是客观内容的客观描述,如测量人的身高、体重等各种身体特征,这些特征在一定的时间内不会有太大幅度的变化,用来测量这些特征的工具也具有极高的信度和效度,因此不论从要了解的内容和用于了解该内容的方式,都是很客观的;二是客观内容的主观描述,如使用问卷量表测量人的各种能力,人的能力应该也是比较恒定的,但用于测量这些特征的工具,无论是编制过程还是施用过程,都避免不了与人为因素有关的干扰,即便硬要说它是客观的,也是“主观”的客观。三是主观内容的主观描述,如各种投射测验,对于这些测验,我没有实际接触过,但从书本上来看,难免不让我认为这种测验从内容到方式都不是那么客观;最后一种就显而易见了,即对主观内容的客观描述,如对推特的文本分析,我要进行的日记文本分析,也是这一范围之内的。日记本身是主观的产物,但这里我要对这些主观的内容进行客观的数据分析,进而从这一角度来加深对自己的了解,不过这个方法的局限性也很大,毕竟不是每个人都有几十万字的日记文本可以用来分析。另外再加一句,上面这段话,也可以说是对客观内容的主观描述。
这篇文章分为三部分,首先是对我每天记日记的时间进行一个简单的分析,然后对文本进行分词,针对词频进行分析,最后是一个初步的情感分析。下面先载入需要用到的包。
导入需要的包
library(tidyverse)
library(readxl)
library(jiebaR)
library(ggthemes)一般情况下,我的第一行代码都是library(tidyverse),这次主要用到了其中dplyr、tidyr、stringr以及ggplot2四个包;readxl包用来读入.xlsx格式的文件;jiebarR用来分词;ggthemes用来添加我最喜欢的tufte主题。
时间分析
首先要把日记中与时间有关的内容提取出来,我记录时间的格式很固定,都是20XX年X月X日 周X XX:XX的形式,通过以下代码,可以把这部分内容提取出来:
time <- read_lines('dairy.txt') %>%
as.tibble() %>%
filter(str_detect(value, '.*年.*月.*日.*周')) %>%
mutate(num = row_number()) %>%
select(2, time = 1)处理后是这个样子的:
| num | time |
|---|---|
| 1 | 2012年1月13日 周五 21:40 |
| 2 | 2012年1月14日 周六 21:41 |
| 3 | 2012年1月15日 周日 21:53 |
| 4 | 2012年1月16日 周一 21:58 |
| 5 | 2012年1月17日 周二 21:45 |
| 6 | 2012年1月18日 周三 21:51 |
| 7 | 2012年1月19日 周四 22:01 |
| 8 | 2012年1月20日 周五 21:43 |
| 9 | 2012年1月21日 周六 21:35 |
| 10 | 2012年1月22日 周日 21:53 |
所有的时间都放在一起是没法分析的,接下来我就把各部分时间分离开,并转化成了整数型,这一步代码如下:
time_sep <- time %>%
separate(time, c('year', 'time'), sep = '年') %>%
separate(time, c('month', 'time'), sep = '月') %>%
separate(time, c('day', 'week', 'time'), sep = ' ') %>%
separate(time, c('hour', 'minute'), sep = ':') %>%
mutate(day = str_remove(day, '日')) %>%
mutate_at(vars('year', 'month', 'day', 'hour', 'minute'), as.integer)此时的数据是这样的:
| num | year | month | day | week | hour | minute |
|---|---|---|---|---|---|---|
| 1 | 2012 | 1 | 13 | 周五 | 21 | 40 |
| 2 | 2012 | 1 | 14 | 周六 | 21 | 41 |
| 3 | 2012 | 1 | 15 | 周日 | 21 | 53 |
| 4 | 2012 | 1 | 16 | 周一 | 21 | 58 |
| 5 | 2012 | 1 | 17 | 周二 | 21 | 45 |
| 6 | 2012 | 1 | 18 | 周三 | 21 | 51 |
| 7 | 2012 | 1 | 19 | 周四 | 22 | 1 |
| 8 | 2012 | 1 | 20 | 周五 | 21 | 43 |
| 9 | 2012 | 1 | 21 | 周六 | 21 | 35 |
| 10 | 2012 | 1 | 22 | 周日 | 21 | 53 |
然后对数据进一步处理,为绘图作准备:
time_month <- time_sep %>%
mutate(time = hour * 60 + minute) %>%
group_by(year, month) %>%
summarise(mtime = mean(time)) %>%
mutate(hour = as.integer(mtime %/% 60),
minute = as.integer(mtime %% 60),
minute = ifelse(minute < 10, str_pad(minute, 2, pad = '0'),
as.character(minute)))数据变成了下面这样:
| year | month | mtime | hour | minute |
|---|---|---|---|---|
| 2012 | 1 | 1312.000 | 21 | 52 |
| 2012 | 2 | 1273.857 | 21 | 13 |
| 2012 | 3 | 1284.484 | 21 | 24 |
| 2012 | 4 | 1298.333 | 21 | 38 |
| 2012 | 5 | 1287.200 | 21 | 27 |
| 2012 | 6 | 1284.893 | 21 | 24 |
| 2012 | 7 | 1298.967 | 21 | 38 |
| 2012 | 8 | 1281.567 | 21 | 21 |
| 2012 | 9 | 1288.067 | 21 | 28 |
| 2012 | 10 | 1270.125 | 21 | 10 |
然后就可以作图了:
time_month %>% ggplot(aes(month, mtime)) +
geom_line(aes(color = as.factor(year)), size = .8) +
geom_text(aes(label = str_c(hour, ':', minute)), size = 1.8,
nudge_y = ifelse(time_month$mtime > 1440, -20, 20)) +
scale_x_continuous(breaks = seq(1, 12, 1)) +
scale_y_continuous(breaks = seq(1260, 1470, 30),
labels = c('21:00', '21:30', '22:00', '22:30',
'23:00', '23:30', '24:00', '24:30')) +
scale_color_brewer(palette = 'Set1') +
facet_wrap(~ year, ncol = 2) +
labs(x = '月 份', y = '时 间') +
theme_light() +
theme(legend.position = 'none', axis.text.y = element_text(size = 6))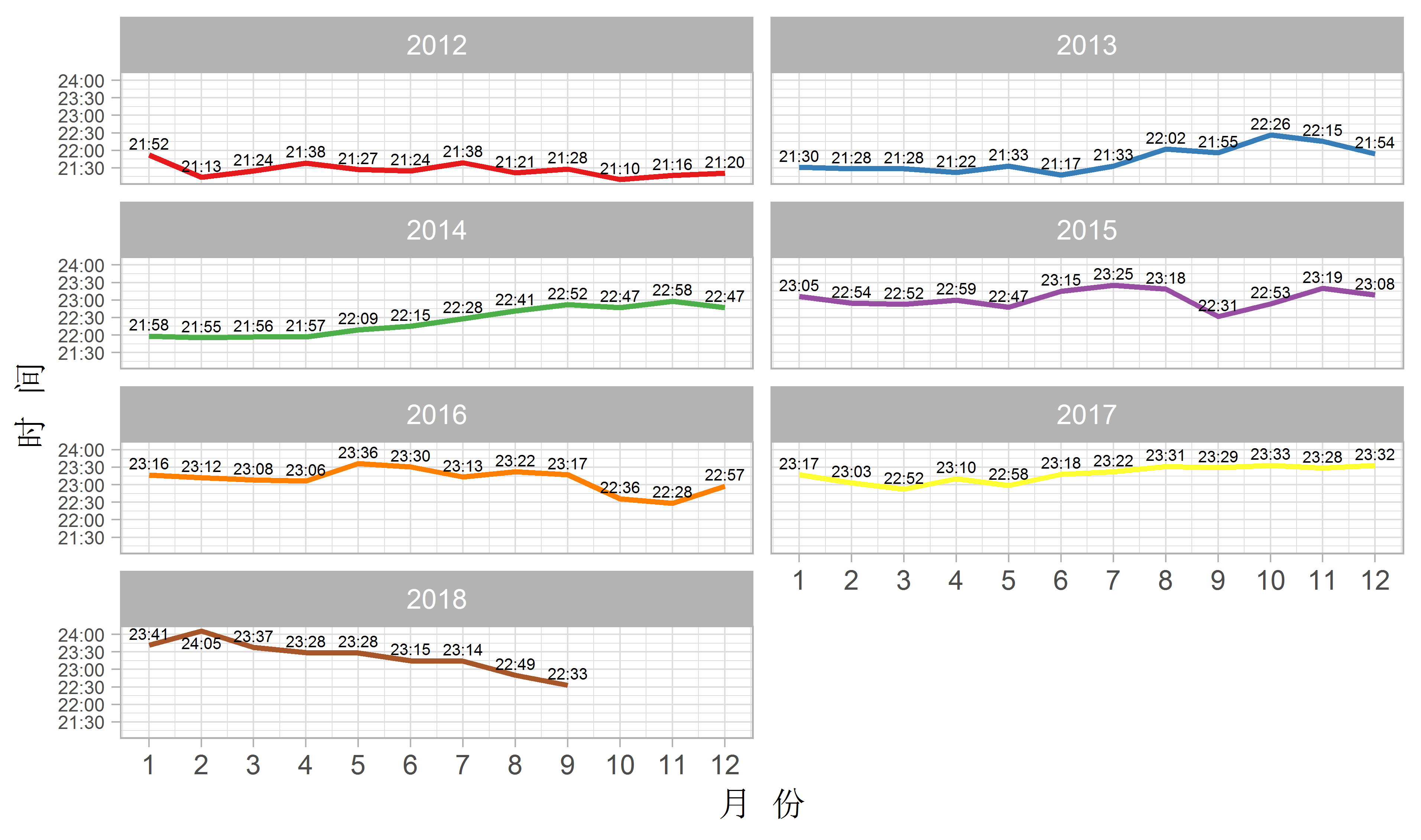
这里我暂且拿记日记的时间来充当睡眠时间的指标,因为我每天记完日记差不多就要去睡觉了。可以看到,12年到13年我睡得还是比较早的,因为要去哄孩子睡觉;14年在准备考研,睡得越来越晚;从15年到18年的读研期间,我睡得就相当晚了,直到最近几个月,因为工作了,所以睡得才早了一点。另外,值得一提的是,我在2018年2月份是睡得最晚的,平均起来,竟然超过了半夜12点才睡。这里,我用了日本深夜档动画的计时方式,如10月8日凌晨一点半,不写成10月8日1:30,而是写成10月7日25:30,这样计算起来比较方便。
这一部分并算不上是什么分析,只是为后面的分析作些数据清洗和作图上的准备,下面来看下词频的情况。
词频分析
先做一些基本的工作:
dairy_full <- read_lines('dairy.txt')
stopwords <- read_lines('stopwords.txt') %>% as.tibble()
worker <- worker(stop_word = 'stopwords.txt')
dairy_full_word <- worker[dairy_full]
dairy_stopwords <- read.csv('dairy_stopwords.txt', stringsAsFactors = FALSE,
header = FALSE) %>%
rename(word = V1)其中dairy_full是整个日记文本,stopwords是我在网上找的中文停用词,worker是用于分词的环境,dairy_full_word是分词后的词汇数据,dairy_stopwords是我根据分词后的结果,进一步增加的停用词。然后进一步整理数据:
dairy_full_word_sort <- dairy_full_word %>%
table() %>%
as.tibble() %>%
select(word = 1, freq = 2) %>%
filter(!str_detect(word, '(\\d+)|([A-Za-z]+)|(\\s+)')) %>%
filter(str_length(word) > 1) %>%
arrange(-freq) %>%
anti_join(dairy_stopwords)这里去掉了数字、字母、空格以及长度小于2的字符,而且去掉了我自定义的停用词。下面开始绘图:
dairy_full_word_sort %>% filter(freq > 290) %>%
ggplot(aes(fct_reorder(word, freq), freq)) +
geom_col(fill = '#870204', width = .9) +
geom_text(aes(label = freq), nudge_y = -20, color = 'white') +
labs(x = '词 汇', y = '频 次') +
scale_y_continuous(expand = c(0, 10)) +
coord_flip() +
theme_tufte()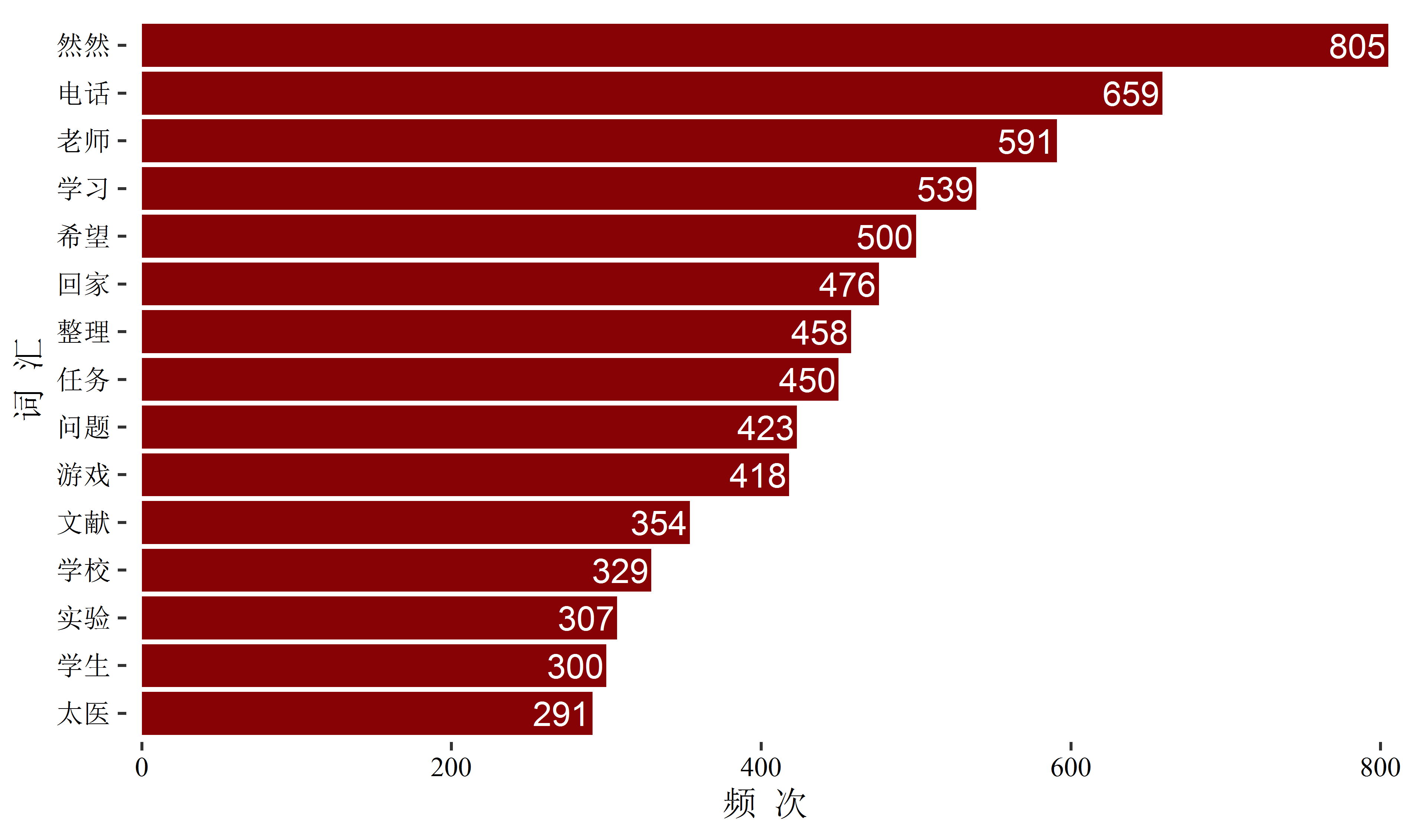
我只呈现了频次最多的十五个有意义的词汇,这些词汇大概可以部分勾勒出我最近几年是个什么样的人了:
第一个词自然是我的宝贝儿子啦,基本上每三天就会在日记里提到一次。
第二个词竟然是电话,我自认为是一个不太喜欢跟人交流的人,但数据显示的结果似乎不是这样,看来主观的想法有时确实是不准确的。
第三个词是老师,我这些年主要是跟老师们打交道,各位老师辛苦了!
第四个词是学习,可以说,学习就是我最大的兴趣了,特别是学了发展心理学专业之后,更加坚定了终身学习的决心,正好最近看的《荀子》也提到:
真积力久则入,学至乎没而后止也。
第五个词是希望,这几年我没少表达愿望啊,不知道实现了几个。
第六个词是回家,在离家不太远的地方读书的好处就是一周可以回好几次家。
第七个词是整理,我也挺喜欢整理东西的,不过仅限于电脑上的东西。
第八个词和第九个词分别是任务和问题,这些年面临着很多任务,遇到了很多问题,就目前的情况来看,大部分的任务和问题都应该解决掉了。
第十个词是游戏,其实后面还有个玩游戏,出现了一百零几次,加起来的话,差不多跟学习频次一样高了,玩游戏和学习对我来说同等重要,从某种意义上讲,学习即是游戏,游戏亦是学习。
第十一到第十三个词分别是文献、学校、实验,都是跟研究生阶段有关的,现在终于跟这些东西彻底告别了。
第十四个词是学生,因为我前几年弄了个辅导班。
最后一个词是太医,没有太医,不可能会有这个博客和这篇文章,我的生命中也会失去很多乐趣。
这是整体的情况,下面再分年份看一下:
dairy_year_word <- read_lines('dairy.txt') %>%
as.tibble() %>%
mutate(num = cumsum(str_detect(value, '.*年.*月.*日.*周'))) %>%
left_join(time) %>%
filter(value != time, str_length(value) > 1) %>%
group_by(num, time) %>%
summarise(text = str_c(value, collapse = '')) %>%
ungroup() %>%
left_join(time_sep) %>%
group_by(year) %>%
summarise(text = str_c(text, collapse = ''))
dairy_year_word_temp <- tibble()
for (i in 1:nrow(dairy_year_word)) {
temp <- worker[dairy_year_word$text[i]]
word_temp <- temp %>%
as.tibble() %>%
mutate(year = 2011 + i)
dairy_year_word_temp <- bind_rows(dairy_year_word_temp, word_temp)
}
dairy_year_word_sort <- dairy_year_word_temp %>%
select(2, word = 1) %>%
filter(!str_detect(word, '(\\d+)|([A-Za-z]+)|(\\s+)')) %>%
filter(str_length(word) > 1) %>%
anti_join(dairy_stopwords) %>%
group_by(year, word) %>%
count() %>%
ungroup() %>%
select(1, 2, freq = 3) %>%
arrange(year, -freq) %>%
group_by(year) %>%
top_n(10, freq) %>%
ungroup() %>%
mutate(order = row_number()) 上面的代码有点多,但实际上都是之前的代码组合起来再稍加修改写成的,没什么新的东西。这时可以继续绘图了:
dairy_year_word_sort %>%
ggplot(aes(order, freq)) +
geom_col(fill = '#870204', width = .8) +
geom_text(aes(label = freq), nudge_y = -10, color = 'white', size = 1.8) +
labs(x = '词 汇', y = '频 次') +
coord_flip() +
scale_y_continuous(expand = c(0, 10)) +
scale_x_reverse(breaks = dairy_year_word_sort$order,
labels = dairy_year_word_sort$word) +
facet_wrap(~ year, scales = 'free_y') +
theme_tufte() +
theme(axis.text.y = element_text(size = 6),
axis.text = element_text(color = 'black'))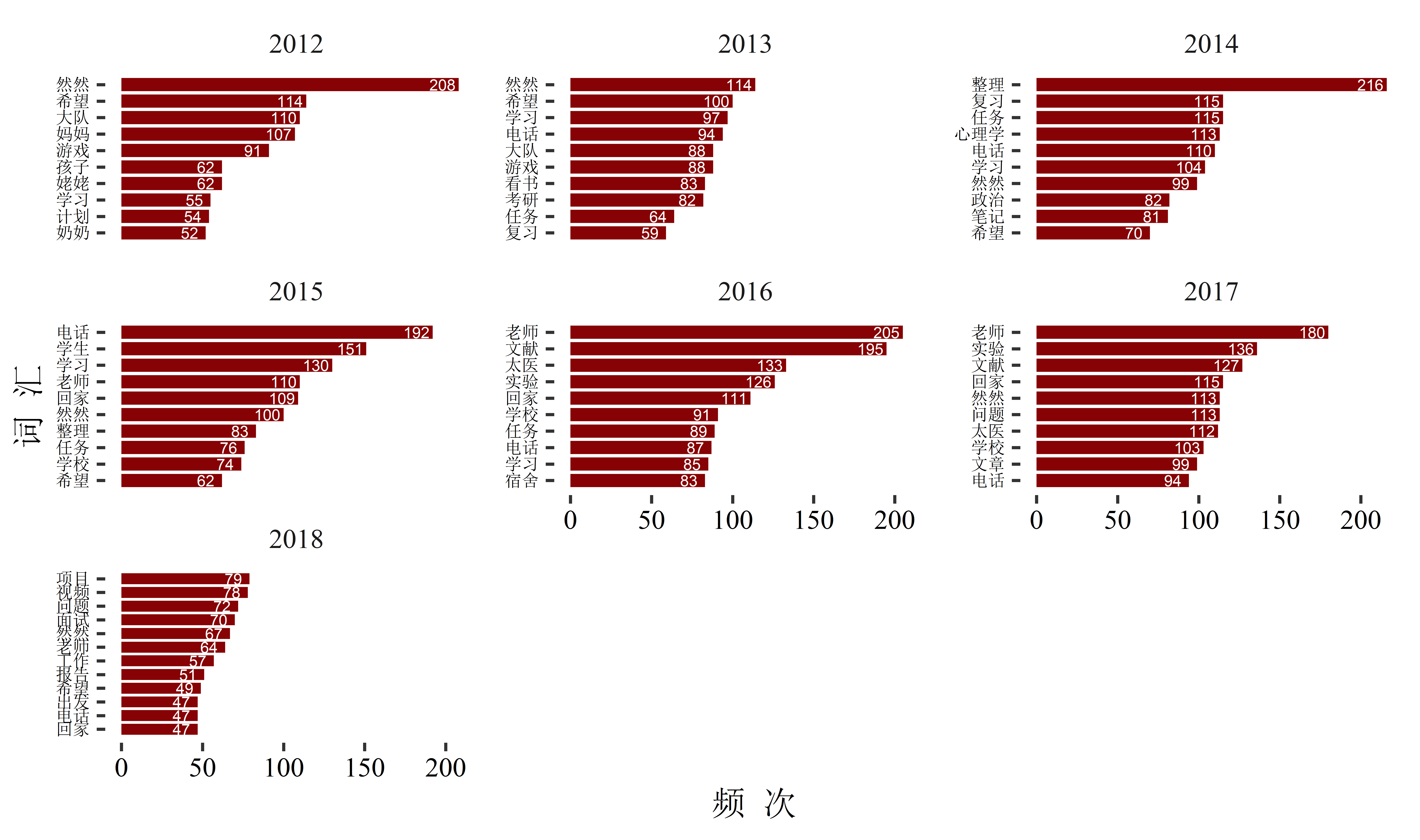
在作这张图时,遇到了一点困难,即分面后的直条图并没有按数量的顺序从多到少排列,查了好久的Stack Overflow,也没找到解决办法,不过后来看到了一篇文章,正好是用来解决这个问题的。
从图中可以看出来,2012年的时候,我主要还是围着孩子转的,但也已经开始制定一些学习的计划了;2013年已经开始为考研做准备;2014年大部分都是跟考研有关的内容了;2015年是过渡的一年,从家里蹲变成了研究生;2016年跟2017年明显能看出来是在读研;最后2018年,就开始出现跟工作相关的词了。
词频的分析就到此结束,下面开始情感分析。
情感分析
情感分析使用的词库是大连理工大学信息检索研究室提供的情感词汇本体库。这个词库信息挺丰富的,但在这里我只使用了极性这一变量,积极词汇赋值为1分,消极词汇赋值为-1分,然后计算总和,得出总分数。首先将词库导入并简单整理:
sentiment <- read_xlsx('情感词汇本体.xlsx') %>%
select(word = 1, sentiment = 7) %>%
filter(sentiment == 1 | sentiment == 2) %>%
mutate(sentiment = ifelse(sentiment > 1, -1, 1))然后进一步清理数据,这次以月份为单位:
dairy_month_word <- read_lines('dairy.txt') %>%
as.tibble() %>%
mutate(num = cumsum(str_detect(value, '.*年.*月.*日.*周'))) %>%
left_join(time) %>%
filter(value != time, str_length(value) > 1) %>%
group_by(num, time) %>%
summarise(text = str_c(value, collapse = '')) %>%
ungroup() %>%
left_join(time_sep) %>%
group_by(year, month) %>%
summarise(text = str_c(text, collapse = ''))
dairy_month_word_temp <- tibble()
for (i in 1:nrow(dairy_month_word)) {
temp <- worker[dairy_month_word$text[i]]
word_temp <- temp %>%
as.tibble() %>%
mutate(year = 2012 + (i - 1) %/% 12,
month = ifelse(i %% 12 > 0, i %% 12, 12))
dairy_month_word_temp <- bind_rows(dairy_month_word_temp, word_temp)
}
dairy_month_word_sort <- dairy_month_word_temp %>%
select(2, 3, word = 1) %>%
filter(!str_detect(word, '(\\d+)|([A-Za-z]+)|(\\s+)')) %>%
filter(str_length(word) > 1) %>%
left_join(sentiment) %>%
filter(!is.na(sentiment)) %>%
group_by(year, month) %>%
summarise(sentiment = sum(sentiment))最后将图绘出:
dairy_month_word_sort %>% ggplot(aes(month, sentiment)) +
geom_line(aes(color = as.factor(year)), size = 1) +
geom_text(aes(label = sentiment), size = 2,
nudge_y = case_when(dairy_month_word_sort$sentiment > 75 ~ -10,
dairy_month_word_sort$sentiment < 10 ~ 10,
TRUE ~ 0)) +
scale_x_continuous(breaks = seq(1, 12, 1)) +
scale_color_brewer(palette = 'Set1') +
facet_wrap(~year, ncol = 2) +
labs(x = '月 份', y = '分 数') +
theme_light() +
theme(legend.position = 'none',
axis.text.y = element_text(size = 7))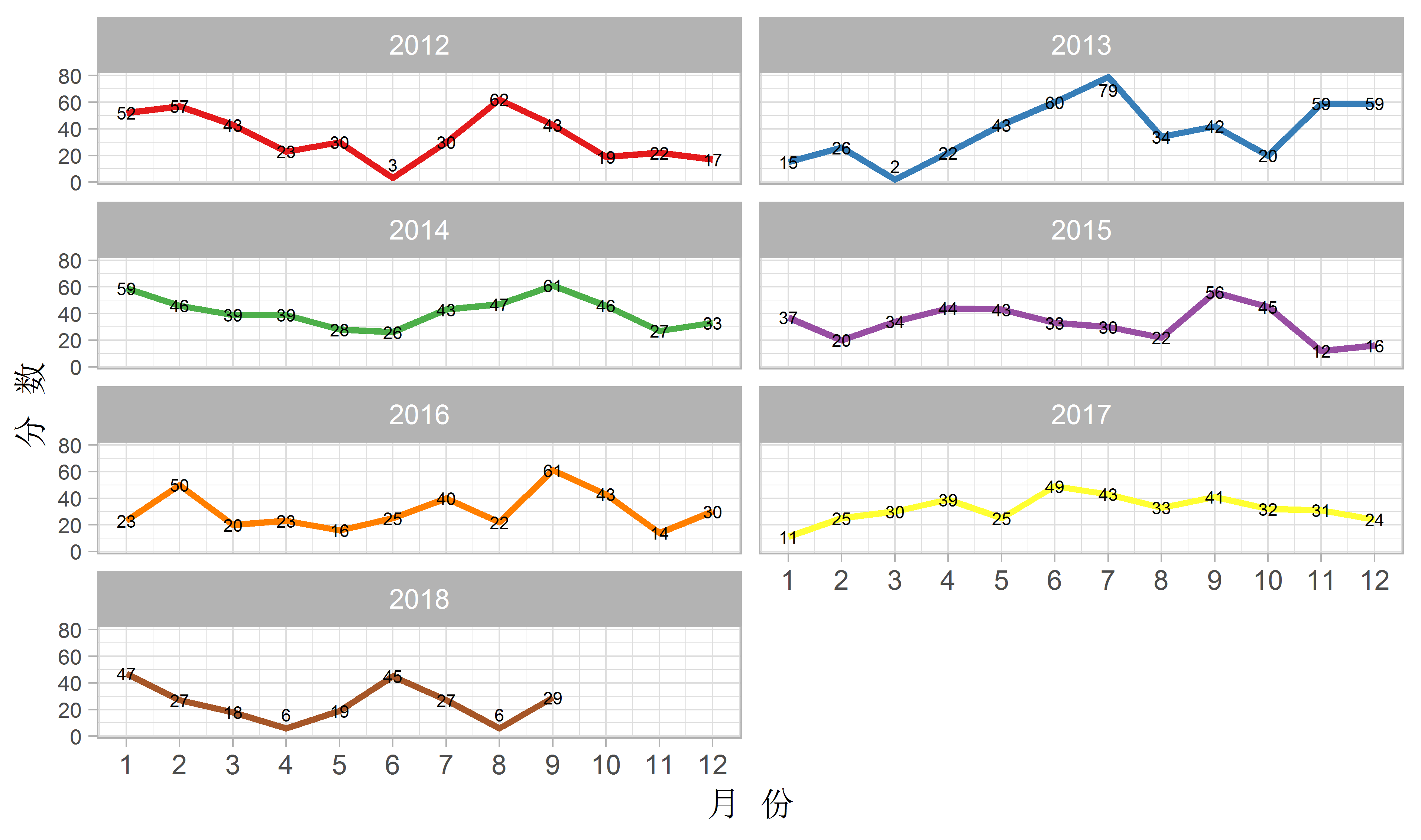
从整体来看,我的情感还是比较积极的,没有出现过负值。分数最低的是2013年的2月份,只有2分,大概是因为当时孩子生病了吧;分数最高的是2013年7月份,79分,那个月我终于通过自考拿到了本科证,所以较长的时间里都保持了愉快的心境。今年有两个月分数都很低,一个是4月份,当时正被毕业论文答辩折磨;另一个是8月份,当时工作有些不顺,而且一直生病,痛苦得很。
这个初步的情感分析就到此为止了,说它是初步的,因为目前的分析是不太准确的,有些词,比如说“高兴”,即便前面有个“不”字,还是会被判定为积极词汇而加1分,要解决这个问题,还要和bigram相结合,不过这次就先不再更进一步的研究了。
新博客的第一篇文章到此结束,希望以后能做到周更,周更不行就月更,月更不行就年更……
希望这个希望可以实现……

